C-Workshop
Urheber: Andre Adrian
Datum: 01.Mai.2015
Einleitung
Das Linux Betriebssystem ist kein klassisches Echtzeitsystem (hard real
time system), es ist aber sehr gut für "soft real time" Anforderungen
verwendbar. Ebenso wenig ist Linux von sich aus redundant, lässt sich aber
auf Hardware-Ebene (Beispiel Doppelnetzteil, Festplatten RAID, ECC RAM), auf
Betriebssystem-Ebene (Beispiel IP-Cluster, Heartbeat Fail-over, LAN
Anschlüsse Link Aggregation) und auf Applikation-Ebene (Beispiel TCP Client für redundante TCP-Server) redundant
machen.
Der C-Workshop soll die Programmierung in C von typischen Aufgaben der
Prozessdatenverarbeitung
(PDV) unter Linux zeigen. Die Schwerpunkte sind:
- Wohl geordneter Zustand von Variablen
- Numerik
- Zeiger/Größe Doppel-Parameter
- Zugriffs-Funktionen
- Prüfsumme (Hashfunktion)
- Programmierung der seriellen Schnittstelle
- Transportkodierung
- Multi Ein-/Ausgabe
- Programmierung von TCP Kommunikation
- Behandlung von interval timer und time outs
- Zustands Übergang Diagramm (state diagram)
- Behandlung von "slow system-calls"
- TCP Client State Diagram für redundante TCP Kommunikation
- TJSON LL(1) Grammatik Parser
- Prozesspriorität
- Call Tree, Call Trace
Redewendungen in Programmiersprachen
Gute Templates, Pattern, Schablonen, Vorlagen, Redewendungen helfen bei der
Programmierung. In diesem Text versuche ich die mir bekannten besten
Schablonen der C Programmierung zu verwenden. Im eigentlichen Text weise ich
nicht auf die einzelnen Vorlagen hin - man sieht sie ja im Quelltext.
Eigentlich ist der ganze C-Workshop eine Sammlung von Redewendungen welche
bei der Programmierung von typischen PDV Aufgaben unter Linux helfen.
Ausblicke auf C++
An einigen Stellen werden C++ Programme vorgestellt. Um die größten Vorteile
von C++ nutzen zu können muss ein C Programmierer nur wenig neues lernen:
Die Klasse (class) und die Fehler Behandlung (try, throw, catch). Übrigens
bietet C++ auch hyperkomplexe Lösungen für die man im Bereich PDV erst noch
die passenden Probleme finden muss...
Quelltext
Den kompletten Quelltext gibt es als tarball für den download. Es dürfte für
das Lernen aber sinnvoller sein die Dateien per Copy und Paste selbst zu
erstellen. Oder gar die Quelltext Zeilen abtippen. Sie wollen das Thema doch
verstehen, oder?
Hier ist der Quelltext: c-workshop_10_src.tgz
Auspacken unter Linux mit
tar xzf c-workshop_10_src.tgz
Es entsteht ein Unterverzeichnis c-workshop mit den Dateien.
Inhaltsverzeichnis
Wohl
geordneter Zustand von Variablen
Die Theorie des state diagrams
(Zustandsübergangsdiagramms)
und damit zusammenhängend die Theorie der state variables
(Zustands-Variablen) ist sehr wichtig für die Programmierung von
fehlerfreier Software. Was ist die Kern-Idee des state diagrams, der state
variables oder der state machine?
Das Programm befindet sich immer in einem wohl geordneten Zustand. In diesem
Zustand haben alle Zustands-Variablen einen sinnvollen Inhalt. Als Reaktion
auf eine Einwirkung von außen (z.B. Benutzer-Eingabe, aber auch Ablauf eines
time outs) ändert die state machine ihren Zustand von einem wohl geordneten
Zustand zu einem anderen wohl geordneten Zustand.
Im Moment des Zustandsüberganges können die Zustands-Variablen in einem
"ungeordneten" Zustand sein, am Ende des Zustandsübergangs müssen die
Zustands-Variablen wieder in einem wohl geordneten Zustand sein.
Programm: An C-String ein Zeichen anhängen
Ein
einfaches Beispiel für Zustands-Variable mit wohl geordneten Zuständen: Eine
C-Funktion soll an einen vorhandenen String s welcher maximal n Bytes
Speicher halten kann ein Zeichen c anhängen. Die Funktion soll heißen
strncatc(s, n, c);
Der Funktions-Header ist
char *strncatc(char *s, int n, const char c);
Vor der Entwicklung der Funktion ist es notwendig über den Normalfall und
die Sonderfälle nachzudenken. Für das Beispiel gilt:
Normalfall: Es gibt einen wohl geordneten Zustand in der Variablen. Die
Variable s ist 0-terminiert (ein korrekter C-String).
Sonderfall 1: Definition der Variablen s. Mit der üblichen Schreibweise
char s[5];
wird die Variable s erzeugt. Der Inhalt von s ist aber nicht wohldefiniert.
Mit
char s[5] = "";
wird die Variable s erzeugt und das erste Byte in s wird mit dem
String-Endzeichen '\0' belegt. Der Inhalt von s ist somit wohldefiniert.
Sonderfall 2: Durch das Anhängen reicht der n Bytes große Speicher nicht
mehr aus. Wegen dem C-String Endzeichen '\0' können in einem n Bytes langen
Speicher maximal n-1 Bytes als String untergebracht werden. Damit der wohl
geordnete Zustand von s erhalten bleibt gibt es mehrere Möglichkeiten.
Üblicherweise wird im Fall von "Speicher voll" kein Zeichen c mehr
angehängt. Diese Sonderfall Behandlung wird truncation (abschneiden)
genannt.
Sonderfall 3: Die Variable c enthält das Zeichen '\0'. Dieses Zeichen kann
wie jedes andere Zeichen behandelt werden. Im Unterschied zu allen anderen
Werten für c wird bei dem Wert '\0' die String-Länge von s nicht erhöht,
d.h. strlen() liefert den selben Wert.
Programm Test
Programm kompilieren mit
gcc -Wall -Wextra -o strncatc strncatc.c
Im xterm Fenster eingeben:
stty -F /dev/tty -icanon
./strncatc
Nach Test wieder Keyboard auf Zeilen-Pufferung stellen
stty -F /dev/tty icanon
Datei
strncatc.c
#include
<stdio.h>
#include <string.h>
// an C-String s mit Speichergroesse n das Zeichen c anhaengen
// Returnwert ist s
char *strncatc(char *s, int n, const char c) {
int len = strlen(s);
if (len + 1 >= n) {
return
s;
// wohlgeordneter Zustand von s
}
s[len] =
c;
// nicht wohlgeordneter Zustand von s
s[len+1] =
'\0';
// wohlgeordneter Zustand von s
return s;
}
int main() {
char s[5] =
"";
// wohlgeordneter Zustand von s
printf("sizeof \"\" = %d\n", sizeof "");
printf("strlen(\"\") = %d\n", strlen(""));
printf(" s = %s\n", s);
for(;;) {
int c = getchar();
strncatc(s, sizeof(s), c);
printf(" s = %s\n", s);
}
return 0;
}
Das strncatc() Beispiel zeigt den korrekten Umgang mit C-String Variablen.
Es wird die Adresse des C-Strings und die Speichergröße des C-Strings als
Zeiger/Größe Doppelparameter übergeben.
Zeiger/Größe Doppelparameter
Diese Zeiger/Größe
Übergabe in zwei Variablen ist weit verbreitet. Ein Beispiel aus
multi_io.c:
read(fdKbd, buf, sizeof buf)
Hier ist buf der Zeiger und sizeof buf die Speichergröße. Ein anderes
Beispiel aus tcp_client.c:
connect(fdServer, (struct sockaddr *)&serv_addr,
sizeof serv_addr)
Hier ist serv_addr der Zeiger und sizeof serv_addr die Speichergrösse.
Programm: C-Strings ohne Zeiger/Größe
Doppelparameter
Die einzige korrekte Alternative zu Zeiger/Größe bei
C-Strings ist die Verwendung von nur einer Größe für alle C-Strings. In
einer Funktion wie strkcatc() kann dann gegen diesen konstanten Wert geprüft
werden:
Datei
strkcatc.c
#include
<stdio.h>
#include <string.h>
#define MAXLEN 100 // C-String Groesse fuer alle C-Strings
im Programm
// an C-String s mit Speichergroesse n das Zeichen c anhaengen
// Returnwert ist s
char *strkcatc(char *s, const char c) {
int len = strlen(s);
if (len + 1 >= MAXLEN) {
return
s;
// wohlgeordneter Zustand von s
}
s[len] =
c;
// nicht wohlgeordneter Zustand von s
s[len+1] =
'\0';
// wohlgeordneter Zustand von s
return s;
}
int main() {
char s[MAXLEN] = "";
// wohlgeordneter Zustand von s
printf("sizeof \"\" = %d\n", sizeof "");
printf("strlen(\"\") = %d\n", strlen(""));
printf(" s = %s\n", s);
for(;;) {
int c = getchar();
strkcatc(s, c);
printf(" s = %s\n", s);
}
}
Sichere
C-String Funktionen
Einige C-Bibliothek-Funktionen sind unsicher.
Funktionen wie gets() oder sprintf() verwenden nicht Zeiger/Größe.
Die Funktionen strcpy_s() und strcat_s() gibt es beim Microsoft C-Compiler.
Für den Gnu C-Compiler sind diese sicheren Funktionen schnell
programmiert.
| unsicher |
sicher |
| gets(char *s) |
fgets(char *s, int size, FILE *stream) |
| sprintf(char *str, const char *format, ...) |
snprintf(char *str, size_t size, const char *format, ...) |
| strcpy(char *dest, const char *src) |
strcpy_s(char *dest, unsigned size, const char *src) |
| strncpy(char *dest, const char *src, size_t n) |
strncpy_s(char *dest, unsigned size, const char *src, size_t
n) |
| strcat(char *dest, const char *src) |
strcat_s(char *dest, unsigned size, const char *src) |
| strncat(char *dest, const char *src, size_t n) |
strncat_s(char *dest, unsigned size, const char *src, size_t
n) |
scanf(const char *format, ...)
fscanf(FILE *stream, const char *format, ...) |
Eingabe zuerst mit fgets() oder fread() einlesen, dann mit
sscanf() verarbeiten |
Programm Test
Programm kompilieren mit
gcc -Wall -o test_string_s test_string_s.c string_s.c
Im xterm Fenster eingeben:
./test_string_s
Das Programm liefert einen Speicherzugriffsfehler. Programm erneut
kompilieren mit
gcc -Wall -fstack-protector-all -o test_string_s test_string_s.c
string_s.c
Das Programm liefert nun die Meldung "stack smashing detected".
Datei
string_s.c
#include
<string.h>
char *strcat_s(char *dest, unsigned n, const char *src) {
strncat(dest, src, n-strlen(dest));
dest[n-1] = '\0'; //
C-String Endzeichen sicherstellen
return dest;
}
char *strcpy_s(char *dest, unsigned n, const char *src) {
strncpy(dest, src, n);
dest[n-1] = '\0'; //
C-String Endzeichen sicherstellen
return dest;
}
Datei
string_s.h
char *strcat_s(char
*dest, unsigned n, const char *src);
char *strcpy_s(char *dest, unsigned n, const char *src);
Datei
test_string_s.c
#include
<stdio.h>
#include <string.h>
#include "string_s.h"
void test_strcat_s() {
char d[16] = "12345678";
const char s[] = "abcdefghABCDEFGH";
strcat_s(d, sizeof d, s);
printf("strcat_s() = %s\n", d);
printf("sizeof d = %d\n", sizeof d);
printf("strlen(d) = %d\n", strlen(d));
}
void test_snprintf() {
char d[16] ="";
const char s1[] = "12345678";
const char s2[] = "abcdefghABCDEFGH";
snprintf(d, sizeof d, "%s%s", s1, s2);
printf("snprintf() = %s\n", d);
printf("sizeof d = %d\n", sizeof d);
printf("strlen(d) = %d\n", strlen(d));
}
void test_strncat() {
char d[16] = "12345678";
const char s[] = "abcdefghABCDEFGH";
strncat(d, s, sizeof
d);
// Achtung: strncat() ist unsicher !
printf("strncat() = %s\n", d);
printf("sizeof d = %d\n", sizeof d);
printf("strlen(d) = %d\n", strlen(d));
}
int main() {
test_strcat_s();
test_snprintf();
test_strncat();
// Achtung: strncat() ist unsicher !
return 0;
}
Variadic Funktionen
Die printf() Funktion ist eine
variadic Funktion, die Anzahl der Parameter ist variabel. Die
Programmiersprache C erlaubt die Programmierung von eigenen variadic
Funktionen. Die Header-Datei stdarg.h stellt die va_ Konstrukte zur
Verfügung. Eine Variable vom Type va_list ist nötig um die optionalen
Parameter in einer variadic Funktion anzusprechen. Dem va_start() Konstrukt
wird der letzte benannte Parameter mitgeteilt. Mit dem va_arg() Konstrukt
wird über die optionalen Parameter iteriert. Die Verarbeitung der optionalen
Parameter wird mit va_end() beendet.
Die Funktion stradd() verkettet mehrere C-Strings, die Funktion strappend()
hängt an einen bestehenden C-String weitere C-Strings an. Die Liste der
optionalen Parameter wird mit einem NULL Zeiger beendet. Beide Funktionen
benutzten den Zeiger/Grösse Doppelparameter für den Ziel-C-String und sind
somit sichere Funktionen.
Programm Test
Programm kompilieren mit
gcc -Wall -o test_stradd test_stradd.c
Im xterm Fenster eingeben:
./test_stradd
Das Programm bittet um die Eingabe von Vorname und Nachname. Mit stradd()
und strappend() werden Vorname, ein Leerzeichen und Nachname verkettet.
Zuletzt wird ein persönliche Begrüssung ausgegeben.
Datei
test_stradd.c
#include
<stdio.h>
#include <string.h>
#include <stdarg.h>
// Strings verketten. NULL Zeiger beendet Liste der Strings.
void stradd(char *dest, unsigned size, ...) {
va_list ap;
char *src;
va_start(ap, size);
while (src = va_arg(ap, char *)) {
while(*dest++ = *src++) {
if (--size <= 1)
{
*dest = '\0';
va_end(ap);
return;
}
}
--dest;
}
va_end(ap);
}
// Strings anhaengen. NULL Zeiger beendet Liste der Strings.
void strappend(char *dest, unsigned size, ...) {
va_list ap;
char *src;
while (*dest) {
++dest;
--size;
}
va_start(ap, size);
while (src = va_arg(ap, char *)) {
while(*dest++ = *src++) {
if (--size <= 1)
{
*dest = '\0';
va_end(ap);
return;
}
}
--dest;
}
va_end(ap);
}
// Entferne Zeilenende Zeichen
// Die Zeichenkette str wird verkuerzt
void strRemoveNewline(char *str) {
char *cr = strchr(str, '\r');
char *nl = strchr(str, '\n');
if (cr != NULL) *cr = '\0';
if (nl != NULL) *nl = '\0';
}
int main(int argc, char *argv[]) {
char vorname[20] = ""; /* Definition
mit Initialisierung */
char nachname[20] = "";
char name[30] = "";
printf("Bitte Vorname eingeben: ");
fgets(vorname, sizeof vorname, stdin);
strRemoveNewline(vorname);
printf("Bitte Nachname eingeben: ");
fgets(nachname, sizeof nachname, stdin);
strRemoveNewline(nachname);
stradd(name, sizeof name, vorname, " ", NULL);
strappend(name, sizeof name, nachname, NULL);
printf("Hallo %s!\n", name);
return 0;
}
Programm: Integer nach Char Umwandlung
Schreiben Sie
ein neues Programm inttochr.c. Dieses Programm ist eine Test-Umgebung für
die Funktion
unsigned char inttochr(int i)
Die Funktion inttochr() soll eine int Variable wohl geordnet in eine
unsigned char Variable umwandeln. Die Sonderfälle sind:
Sonderfall 1: Wenn int Variable < 0 ist, dann soll char Variable = 0
werden
Sonderfall 2: Wenn int Variable > 255, dann soll char Variable = 255
werden
Diese Sonderfall Behandlung heißt saturation (Sättigung).
Benutzen Sie folgende Vorlage:
Datei
inttochr.c
#include
<stdio.h>
#include <stdlib.h>
unsigned char inttochr(int i) {
return i;
}
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "usage: inttochr number\n");
exit(1);
}
int n = atoi(argv[1]);
unsigned char c = inttochr(n);
printf("%d = inttochr(%d)\n", c, n);
return 0;
}
Programm: Mit Uhrzeiten rechnen
Die übliche
Uhrzeit-Darstellung ist Stunde:Minute:Sekunde. Dabei dauert ein Tag von
00:00:00 bis 23:59:59. Diese Darstellung ist für Berechnungen im Computer
schlecht geeignet. Im Programm zeit.c wird die Umwandlung zwischen externer
Darstellung in Stunde:Minute:Sekunde und interner Darstellung in
Sekunden gezeigt. Die Rechnung mit Uhrzeiten wird auch gezeigt.
Umwandlung zwischen Stunde:Minute:Sekunde und
Sekunden
Die Umrechnung ist Sekunden = 3600 * Stunde + 60 * Minute +
Sekunde.
Die umgekehrte Umrechnung ist
Stunde = Sekunden / 3600
Dabei ist / die Integer Division. Beispiel: 7/2 ergibt 3 bei der Integer
Division.
Sekunden = Sekunden - 3600 * Stunde
Nun sind von Sekunden die vollen Stunden abgezogen.
Minute = Sekunden / 60
Sekunde = Sekunden - 60 * Minute
Uhrzeit Addition
In der Sekunden Darstellung ist
die Uhrzeit Addition eine Integer Addition. Eine wohl geordnete Variable
enthält immer einen Wert kleiner 24*60*60 = 86400. Dieser Wert sind die
Sekunden eines Tages. Nach der Integer Addition kann ein Wert größer 86400
entstehen. Dann muss 86400 abgezogen werden um die Uhrzeit Variable zu
normalisieren (wieder in den Bereich der wohldefinierten Variablen bringen).
Diese Sonderfall Behandlung wird Modulo-N Arithmetik genannt (mit
N=86400).
Programm Test
Programm kompilieren mit
gcc -Wall -o zeit zeit.c
Programm-Aufruf mit den beiden Uhrzeiten 10:29:01 und 15:30:59
./zeit 10 29 01 15 30 59
Übung
1
Ändern Sie zeit.c nach zeit1.c. Programmieren Sie die Funktion
ZEIT ZEIT_sub(ZEIT z1, ZEIT z2);
um die Uhrzeit z2 von der Uhrzeit z1 abzuziehen. Das Ergebnis soll eine
normalisierte Uhrzeit im Bereich 0 bis 86399 sein. Fügen Sie nach dem
printf("Zeit Summe ...) ein weiteres printf("Zeit Differenz ...) ein.
Übung
2
Die Eingangsparameter von ZEIT_fromHMS() werden nicht überprüft. Legen
Sie zuerst fest was die gültigen Werte für h, m und s sind. Ändern Sie dann
zeit1.c nach zeit2.c. Bei schlechten Eingangsparametern soll die Funktion
ZEIT_fromHMS() als return value -1 liefern. Prüfen Sie den return value und
beenden Sie wenn nötig das Programm nach einer fprintf() Fehlermeldung mit
exit(). Testen Sie das Programm mit allen möglichen schlechten
Eingangsparametern (h zu klein, h zu groß, m zu klein, m zu groß, s zu
klein, s zu groß).
Datei
zeit.c
#include
<stdio.h>
#include <stdlib.h>
#define EINTAG (24*60*60)
typedef int ZEIT;
ZEIT ZEIT_fromHMS(int h, int m, int s) {
return 3600 * h + 60 * m + s;
}
ZEIT ZEIT_add(ZEIT z1, ZEIT z2) {
ZEIT sum = z1 + z2;
if (sum >= EINTAG) {
sum -= EINTAG;
}
return sum;
}
void ZEIT_toHMS(int z, int *h, int *m, int *s) {
*h = z / 3600;
z -= 3600 * (*h); // die vollen Stunden abziehen
*m = z / 60;
*s = z - 60 * (*m); // die vollen Minuten abziehen
}
int main(int argc, char *argv[]) {
if (argc != 7) {
fprintf(stderr, "usage: zeit h1 m1 s1 h2 m2 s2\n");
exit(1);
}
int h1 = atoi(argv[1]);
int m1 = atoi(argv[2]);
int s1 = atoi(argv[3]);
ZEIT z1 = ZEIT_fromHMS(h1, m1, s1);
int h2 = atoi(argv[4]);
int m2 = atoi(argv[5]);
int s2 = atoi(argv[6]);
ZEIT z2 = ZEIT_fromHMS(h2, m2, s2);
ZEIT sum = ZEIT_add(z1, z2);
int h, m, s;
ZEIT_toHMS(sum, &h, &m, &s);
printf("Zeit Summe = %02d:%02d:%02d\n", h, m, s);
return 0;
}
Programm: Ausnahmebehandlung in C
Die
Ausnahmebehandlung (exception handling) in C erfolgt mit den Funktionen
setjmp() und longjmp(). Die setjmp() Funktion erfüllt die Aufgaben von try
und catch, die longjmp() Funktion entspricht throw.
Datei
zeitd.c
#include
<stdio.h>
#include <stdlib.h>
#include <setjmp.h>
#define EINTAG (24*60*60)
typedef int ZEIT;
jmp_buf zeitd_try;
ZEIT ZEIT_fromHMS(int h, int m, int s) {
if (h < 0 || h > 23 || m < 0 || m > 59 || s < 0 || s
> 61) {
longjmp(zeitd_try,
-1); // throw
}
return 3600 * h + 60 * m + s;
}
ZEIT ZEIT_add(ZEIT z1, ZEIT z2) {
ZEIT sum = z1 + z2;
if (sum >= EINTAG) {
sum -= EINTAG;
}
return sum;
}
void ZEIT_toHMS(int z, int *h, int *m, int *s) {
*h = z / 3600;
z -= 3600 * (*h); // die vollen Stunden abziehen
*m = z / 60;
*s = z - 60 * (*m); // die vollen Minuten abziehen
}
int main(int argc, char *argv[]) {
if (argc != 7) {
fprintf(stderr, "usage: zeit h1 m1 s1 h2 m2 s2\n");
exit(1);
}
int zeitd_catch = setjmp(zeitd_try);
if (0 == zeitd_catch)
{
// try
int h1 = atoi(argv[1]);
int m1 = atoi(argv[2]);
int s1 = atoi(argv[3]);
ZEIT z1 = ZEIT_fromHMS(h1, m1, s1);
int h2 = atoi(argv[4]);
int m2 = atoi(argv[5]);
int s2 = atoi(argv[6]);
ZEIT z2 = ZEIT_fromHMS(h2, m2, s2);
ZEIT sum = ZEIT_add(z1, z2);
int h, m, s;
ZEIT_toHMS(sum, &h, &m, &s);
printf("Zeit Summe = %02d:%02d:%02d\n", h, m, s);
}
else
{
// catch
fprintf(stderr,"catch mit value = %d erhalten\n",
zeitd_catch);
}
return 0;
}
Ausblick: Uhrzeiten rechnen als C++ Programm
Die
Schreibweise des C Programms zeit.c erscheint seltsam solange man nicht die
C++ Versionen des Programms kennt. Dann wird klar das die Schreibweise
ZEIT_add() in C die Schreibweise ZEIT::add() in C++ vorweg nehmen will.
Das Programm zeita.cpp ist noch sehr nahe an der Vorlage zeit.c. Das
Programm zeitb.cpp benutzt die C++ Eigenschaften
- Konstruktor mit Parameter aufrufen
- Operator überladen
Das Programm zeitc.cpp benutzt noch Exceptions (Fehler Ausnahme).
Programm Test
Programm kompilieren mit
g++ -Wall -o zeita zeita.cpp
g++ -Wall -o zeitb zeitb.cpp
g++ -Wall -o zeitc zeitc.cpp
Programm-Aufruf mit den beiden Uhrzeiten 10:29:01 und 15:30:59
./zeita 10 29 01 15 30 59
./zeitb 10 29 01 15 30 59
./zeitc 10 29 01 15 30 59
Übung
Keine. Einfach nur den C++ Quelltext ansehen
und überlegen ob C++ die Mühe wert ist. Hier ein kleiner C++ mit C
Vergleich:
| C++ |
C |
| class |
struct und Funktionen mit struct-Zeiger *this als ersten
Parameter |
| try, throw, catch |
setjmp(), longjmp() |
| Operator überladen |
nicht möglich, Funktionen anstelle von Operatoren nutzen |
Datei
zeita.cpp
#include
<cstdio>
#include <cstdlib>
#define EINTAG (24*60*60)
class ZEIT {
int z;
public:
void fromHMS( int h, int m, int s);
void add(ZEIT z1, ZEIT z2);
void toHMS(int *h, int *m, int *s);
};
void ZEIT::fromHMS( int h, int m, int s) {
z = 3600 * h + 60 * m + s;
};
void ZEIT::add(ZEIT z1, ZEIT z2) {
z = z1.z + z2.z;
if (z >= EINTAG) {
z -= EINTAG;
}
};
void ZEIT::toHMS(int *h, int *m, int *s) {
*h = z / 3600;
z -= 3600 * (*h);
*m = z / 60;
*s = z - 60 * (*m);
};
int main(int argc, char *argv[]) {
if (argc != 7) {
fprintf(stderr, "usage: zeita h1 m1 s1 h2 m2 s2\n");
exit(1);
}
int h1 = atoi(argv[1]);
int m1 = atoi(argv[2]);
int s1 = atoi(argv[3]);
ZEIT z1;
z1.fromHMS(h1, m1, s1);
int h2 = atoi(argv[4]);
int m2 = atoi(argv[5]);
int s2 = atoi(argv[6]);
ZEIT z2;
z2.fromHMS(h2, m2, s2);
ZEIT sum;
sum.add(z1, z2);
int h, m, s;
sum.toHMS(&h, &m, &s);
printf("Zeit Summe = %02d:%02d:%02d\n", h, m, s);
return 0;
}
Datei
zeitb.cpp
#include
<cstdio>
#include <cstdlib>
#define EINTAG (24*60*60)
class ZEIT {
int z;
public:
ZEIT() { z = 0;
}; //
Konstruktor ohne Parameter
ZEIT(int h, int m, int s) { // Konstruktor mit
Parameter
z = 3600 * h + 60 * m + s;
};
ZEIT operator+(ZEIT z1) { // Operator
Ueberladung
z += z1.z;
if (z >= EINTAG) {
z -= EINTAG;
}
return *this;
};
void toHMS(int *h, int *m, int *s) {
*h = z / 3600;
z -= 3600 * (*h);
*m = z / 60;
*s = z - 60 * (*m);
};
};
int main(int argc, char *argv[]) {
if (argc != 7) {
fprintf(stderr, "usage: zeitb h1 m1 s1 h2 m2 s2\n");
exit(1);
}
int h1 = atoi(argv[1]);
int m1 = atoi(argv[2]);
int s1 = atoi(argv[3]);
ZEIT z1(h1, m1, s1); // Konstruktor
benutzen
int h2 = atoi(argv[4]);
int m2 = atoi(argv[5]);
int s2 = atoi(argv[6]);
ZEIT z2(h2, m2, s2);
ZEIT sum = z1 + z2; // Operator
Ueberladung benutzen
int h, m, s;
sum.toHMS(&h, &m, &s);
printf("Zeit Summe = %02d:%02d:%02d\n", h, m, s);
return 0;
}
Datei
zeitc.cpp
#include
<cstdio>
#include <cstdlib>
#define EINTAG (24*60*60)
class ZEIT {
int z;
public:
ZEIT() { z = 0;
};
// Konstruktor ohne Parameter
ZEIT(int h, int m, int s) { //
Konstruktor mit Parameter
if (h < 0 || h > 23 || m < 0 || m > 59 || s
< 0 || s > 61) {
throw
-1;
// Exception ausloesen
}
z = 3600 * h + 60 * m + s;
};
ZEIT operator+(ZEIT z1)
{ // Operator
Ueberladung
z += z1.z;
if (z >= EINTAG) {
z -= EINTAG;
}
return *this;
};
void toHMS(int *h, int *m, int *s) {
*h = z / 3600;
z -= 3600 * (*h);
*m = z / 60;
*s = z - 60 * (*m);
};
};
int main(int argc, char *argv[]) {
if (argc != 7) {
fprintf(stderr, "usage: zeitc h1 m1 s1 h2 m2 s2\n");
exit(1);
}
try
{
// Exception Block
int h1 = atoi(argv[1]);
int m1 = atoi(argv[2]);
int s1 = atoi(argv[3]);
ZEIT z1(h1, m1,
s1); //
Konstruktor benutzen
int h2 = atoi(argv[4]);
int m2 = atoi(argv[5]);
int s2 = atoi(argv[6]);
ZEIT z2(h2, m2, s2);
ZEIT sum = z1 +
z2;
// Operator Ueberladung benutzen
int h, m, s;
sum.toHMS(&h, &m, &s);
printf("Zeit Summe = %02d:%02d:%02d\n", h, m, s);
}
catch (int err)
{
// Exception Handler
fprintf(stderr, "zeitc exception: %d\n", err);
exit(1);
}
return 0;
}
Programm: Zugriffs-Funktionen für globale C-String
Variable
Manchmal liest man kluge Sätze wie "vermeiden Sie globale
Variablen". Dieser Rat läßt sich in der Praxis nicht umsetzen.
Zustands-Variablen müssen meistens als globale Variablen definiert werden.
Ein guter Rat ist hingegen "globale Variablen dürfen nur über
Zugriffs-Funktionen geändert werden". Dadurch wird sichergestellt das ihr
Inhalt immer wohldefiniert bleibt.
Damit eine globale Variable vor dem direkten Zugriff geschützt wird müssen
in der Programmiersprache C mindestens zwei C Quelltext Dateien und eine
Header Datei verwendet werden:
- in der Variable Definition C Datei wird die globale Variable mit der
Speicherklasse static definiert und es werden die Zugriffs-Funktionen
definiert.
- in der Header Datei werden die Funktionsprototypen der
Zugriffs-Funktionen genannt.
- in den Variable Nutzung C Dateien ist die globale Variable unbekannt
und kann nur über die Zugriffs-Funktionen angesprochen werden.
Die globale Variable hat den Name userName. Die Zugriffs-Funktionen
sind
- userName_set() um den Inhalt der Variablen zu ändern
- userName_get() um die Adresse der Variablen zu holen
- userName_cpy() um eine Kopie der Variablen zu erzeugen
Das Programm palindrom testet ob der Inhalt von userName ein Palindrom
ist. Hierzu werden die Funktion strreverse() und strcasecmp() benutzt. Beide
Funktionen arbeiten nur mit dem ASCII Zeichensatz. Umlaute funktionieren
nicht.
Programm Test
Programm kompilieren mit
gcc -Wall -o palindrom palindrom.c username.c string_s.c
Programm-Aufruf
./palindrom Reliefpfeiler
Übung
1
Testen Sie das Programm mit langen Namen wie
Karl-Otto-der-Zweiundvierzigste. Ändern Sie das Programm damit Namen bis zu
einer Länge von 100 Zeichen korrekt verarbeitet werden.
Tipp: Sie müssen zwei Zahlen-Konstanten ändern, mehr nicht!
Übung
2
Das Programm palindrom1.c soll die gleiche Aufgabe ausführen, aber
nicht mehr die Zugriffs-Funktion userName_cpy() verwenden.
Datei
username.h
#ifndef
_USERNAME_H
#define
_USERNAME_H
// Zugriffs Funktionen fuer C-String
userName globale Variable
void userName_set(const char *s);
const char *userName_get();
void userName_cpy(char *s, int n);
#endif
Datei
username.c
#include
"string_s.h"
#include "username.h"
static char userName[20] = "";
void userName_set(const char *s) {
strcpy_s(userName, sizeof userName, s);
}
const char *userName_get() {
return userName;
}
void userName_cpy(char *s, int n) {
strcpy_s(s, n, userName);
}
Datei
palindrom.c
#include
<stdio.h>
#include <stdlib.h>
#include <string.h>
#include "username.h"
// String rueckwaerts
void strreverse(char *s)
{
int a = 0;
int z = strlen(s)-1;
while (a < z) {
char tmp = s[a]; // Dreier Tausch
s[a] = s[z];
s[z] = tmp;
++a;
--z;
}
}
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "usage: palindrom userName\n");
exit(1);
}
userName_set(argv[1]);
printf("userName ist %s\n", userName_get());
char s[40] = "";
userName_cpy(s, sizeof s);
strreverse(s);
printf("userName rueckwaerts ist %s\n", s);
int rv = strcasecmp(userName_get(), s);
if (0 == rv) {
printf("userName ist ein Palindrom\n");
}
return 0;
}
Ausblick: Zugriffs-Funktionen in C++ für C-String
Variablen
In der C Lösung sind die Variable userName und die
Zugriffsfunktionen wie userName_set() ganz eng verbunden.
In der C++ Lösung lassen sich die Variable und ihre Zugriffsfunktionen
voneinander trennen. Die Klasse CSTRING20 erlaubt beliebig vielen 20 Zeichen
langen C-String Variablen den Schutz durch die Zugriffsfunktionen. Diese
Verallgemeinerung von Zugriffsfunktionen ist der Kern der objekt
orientierten Programmierung (OOP).
In der C++ Standardbibliothek gibt es die Klasse string welche umfangreicher
und flexibler als CSTRING20 ist. Siehe z.B. das Buch C++ von A bis Z von
Jürgen Wolf Kapitel 7.1 Die String-Bibliothek (string-Klasse).
Programm Test
Programm kompilieren mit
g++ -Wall -o palindroma palindroma.cpp cstring20.cpp string_s.c
Programm-Aufruf
./palindroma Reliefpfeiler
Übung
Keine. Einfach nur den C++ Quelltext ansehen
und überlegen ob C++ die Mühe wert ist.
Datei
cstring20.hpp
#ifndef
_CSTRING20_HPP
#define
_CSTRING20_HPP
class CSTRING20 {
char cstr[20];
public:
CSTRING20();
void set(const char *s);
const char *get();
void cpy(char *s, unsigned n);
};
#endif
Datei
cstring20.cpp
#include
<cstring>
#include "string_s.h"
#include "cstring20.hpp"
CSTRING20::CSTRING20() { // Konstruktor
cstr[0] =
'\0'; // erzeugt
wohlgeordnete Variable
}
void CSTRING20::set(const char *s) {
strcpy_s(cstr, sizeof cstr, s);
}
const char *CSTRING20::get() {
return cstr;
}
void CSTRING20::cpy(char *s, unsigned n) {
strcpy_s(s, n, cstr);
}
Datei
palindroma.cpp
#include
<cstdio>
#include <cstdlib>
#include <cstring>
#include "cstring20.hpp"
// String rueckwaerts
void strreverse(char *s)
{
int a = 0;
int z = strlen(s)-1;
while (a < z) {
char tmp = s[a]; // Dreier Tausch
s[a] = s[z];
s[z] = tmp;
++a;
--z;
}
}
CSTRING20 userName;
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "usage: palindrom userName\n");
exit(1);
}
userName.set(argv[1]);
printf("userName ist %s\n", userName.get());
char s[40] = "";
userName.cpy(s, sizeof s);
strreverse(s);
printf("userName rueckwaerts ist %s\n", s);
int rv = strcasecmp(userName.get(), s);
if (0 == rv) {
printf("userName ist ein Palindrom\n");
}
return 0;
}
Programm: ASCII Datei in Großbuchstaben wandeln
In
diesem Programm geht es um die gepufferte Ein-/Ausgabe (stream-io,
Datenstrom-Ein/Ausgabe) unter Linux. Der Dateiname einer ASCII Datei wird
als Parameter übergeben. Der Dateiinhalt in Großbuchstaben wird auf stdout
ausgegeben. Die drei Filepointer stdin, stdout und stderr stehen jedem
C-Programm direkt zur Verfügung.
| Filepointer |
file-descriptor |
Bedeutung |
| stdin |
STDIN_FILENO |
Standard Eingabe, üblicherweise die Tastatur |
| stdout |
STDOUT_FILENO |
Standard Ausgabe, üblicherweise das xterm Fenster |
| stderr |
STDERR_FILENO |
Standard Fehlerausgabe, üblicherweise das xterm Fenster |
Der Aufruf
./toupper toupper.c
liefert die Ausgabe:
/* TOUPPER.C
*
* GCC -WALL -O TOUPPER TOUPPER.C
*
*/
#INCLUDE <STDIO.H>
#INCLUDE <STDLIB.H>
#INCLUDE <STRING.H>
#INCLUDE <CTYPE.H>
// STRING IN GROSSBUCHSTABEN WANDELN
VOID STRTOUPPER(CHAR *S) {
...
Programm Test
Programm kompilieren mit
gcc -Wall -o toupper toupper.c
Im xterm Fenster eingeben:
./toupper toupper.c
Übung
1
Die Variable buf hat eine Größe von 100 Zeichen. Ändern Sie für die
Datei toupper1.c die Größe auf 2 Zeichen und lassen Sie das Programm laufen.
Gibt es Unterschiede in der Ausgabe? Testen Sie die Programmlaufzeit der
beiden Versionen mit
time ./toupper toupper.c
time ./toupper1 toupper.c
Was bemerken Sie?
Was passiert bei Puffer-Größe 1? Warum?
Übung
2
Ändern Sie die Datei toupper.c in tolower.c. Der Dateiinhalt soll nun
in Kleinbuchstaben umgewandelt werden.
Tipp: Sie müssen nur eine Quelltextzeile ändern.
Datei
toupper.c
#include
<stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
// String in Grossbuchstaben wandeln
void strtoupper(char *s) {
int i;
for (i = 0; s[i] != '\0'; ++i) {
s[i] = toupper(s[i]);
}
}
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "usage: toupper file\n");
exit(1);
}
FILE *fp = fopen(argv[1], "r");
if (NULL == fp) {
perror("toupper fopen");
exit(1);
}
for(;;)
{
// Endlosschleife
char buf[100];
char *rv = fgets(buf, sizeof buf, fp);
if (NULL == rv)
break;
// Schleife beenden
strtoupper(buf);
printf("%s", buf);
}
fclose(fp);
return 0;
}
Information hiding in der C Bibliothek
Der Programmierer "sieht" in C von einer Datei nur einen File Deskriptor,
eine Integer Zahl, oder einen File Pointer, einen Zeiger. In der C
Bibliothek ist der File Deskriptor der Index in ein Array von File
Speicherstrukturen. Der File Pointer ist die Adresse der File
Speicherstruktur. Die Idee von "Handles" wie File Deskriptor und File
Pointer können natürlich auch für das Information hiding in eigenen
Applikationen eingesetzt werden: Ein Modul verwaltet Ressourcen. Der
Speicher für jede Ressource ist lokaler (static) Speicher im Modul.
Außerhalb des Moduls ist die Ressource nur über den Handle, einen einfachen
Datentype wie ein Integer oder ein Zeiger, bekannt.
Bei graphischen Oberflächen werden gerne Handles benutzt. Ein Fenster wird
oft über seinen Handle angesprochen.
Programm: Prüfsumme (Hashfunktion)
Eine
Datenübertragung wird oft durch eine Prüfsumme abgesichert. Die hier
vorgestellte Prüfsumme
hat eine Länge von 24 Bits. Im Sender wird vor der Datenübertragung aus den
Daten die Prüfsumme berechnet. Dann werden Daten und Prüfsumme an den
Empfänger übertragen. Der Empfänger berechnet die Prüfsumme erneut und
vergleicht die berechnete Prüfsumme mit der empfangenen Prüfsumme. Haben
beide Prüfsummen den gleichen Wert, gibt es eine hohe Wahrscheinlichkeit,
dass die Daten korrekt empfangen wurden. Die vorgestellte Prüfsumme wird
nach der Divisionsrestmethode
berechnet. Die Daten bilden den Zähler und eine Primzahl bildet den Nenner
für die Modulo (Divisionsrest) Berechnung. Der Divisionsrest ist die
Prüfsumme, eine sehr gute Prüfsumme sogar.
Mit den Prüfsummen-Algorithmen läßt sich auch ein Hash-Speicher betreiben.
Die Hashfunktion
berechnet aus Teilen des Datensatzes wie Kunden-Name einen Hash-Wert. Dieser
Hash-Wert wird als Index für die Abspeicherung im Hash-Speicher, einem Array
von Datensätzen, benutzt. Ein Datensatz wird aus dem Hash-Speicher gelesen
indem erneut ein hashing des Kunden-Name durchgeführt wird. Der Hash-Wert
bestimmt den Speicherplatz des Kunden-Datensatzes. Zwei Kunden mit dem Namen
"Hans Meier" erhalten den gleichen Hash-Wert, eine Hash-Kollision liegt vor.
Eine solche Kollision wird beim Schreiben in den Hash-Speicher erkannt, wenn
der Datensatz im Hash-Speicher schon belegt ist. Strategien gegen
Hash-Kollision sollen hier nicht weiter besprochen werden.
Programm Test
Programm kompilieren mit
gcc -Wall -o hashwert hashwert.c
Im xterm Fenster eingeben:
./hashwert
Datei
hashwert.c
#include
"stdio.h"
#include "string.h"
/* Berechne 24 Bit Hashwert nach
Divisionsrestmethode
* in: 7 Bit ASCII Zeichenkette,
0 terminiert
* out: Hashwert als Long
Integer
*/
long hashwert(const char *d)
{
int length =
strlen(d), n = 0;
long r =
0;
while (n <
length) {
r = (128 * r + d[n++]) % 16777213; // Nenner ist
Primzahl
}
return
r;
}
int main() {
char str[] = "The
quick brown fox jumps over the lazy dog";
long hw =
hashwert(str);
printf("Text ist
\"%s\"\n", str);
printf("Hashwert
ist %lx hexadezimal\n", hw);
return
0;
}
Programm: Prüfsumme CRC-32
Die Prüfsumme nach der
Divisionsrestmethode ist einfach in Software zu programmieren. Einfach in
Hardware zu realisieren ist der Cyclic Redundancy Check (CRC). Im
Ethernet-Standard IEEE 802.3 wird die Erzeugung der 32 Bit langen CRC-32
Prüfsumme erklärt. Das Programm crc32.c liefert für einen 0-terminierten
ASCII String die CRC-32 Prüfsumme. Die Berechnung der CRC-32 im Sender und
die Überprüfung der CRC-32 im Empfänger wird üblicherweise in Hardware
ausgeführt. Eine Datenübertragung über V.24 kann hardwaremässig mit einem
Paritätsbit pro Datenbyte abgesichert werden. Anstelle der vielen
Paritätsbits kann eine CRC-32 Prüfsumme am Ende der V.24 Meldung benutzt
werden.
Der Empfänger berechnet aus den Daten die CRC-32 Prüfsumme erneut. Sind die
im Empfänger berechnete Prüfsumme und die von Sender gesandte Prüfsumme
gleich, dann besteht eine sehr hohe Wahrscheinlichkeit, daß die empfangene
Meldung der abgesandten Meldung entspricht.
Programm Test
Programm kompilieren mit
gcc -Wall -o crc32 crc32.c
Im xterm Fenster eingeben:
./crc32
Datei
crc32.c
#include
<stdio.h>
#include <string.h>
/* CRC-32
Polynom
= 0x04C11DB7
* als
Binaerzahl
= 0000 0100 1100 0001 0001 1101 1011 0111
* von rechts nach links gelesen = 1110 1101 1011 1000 1000 0011 0010
0000
* als
Hexzahl
= 0xEDB88320
*/
/* CRC-32 nach IEEE 802.3 (Ethernet) berechnen fuer 0-terminierten C-String
*/
unsigned long crc32(const char *str)
{
int j, length = strlen(str);
unsigned long crc32_rev = 0xffffffff; //
Schieberegister, Startwert (111...)
for (j = 0; j < length; ++j) { // Schleife ueber
alle Zeichen
int i, mask = 0x01; // LSB Bit
maskieren
for (i = 0; i < 8; ++i) { //
Schleife ueber Bits im Zeichen
unsigned bit = (str[j] & mask) ? 1 :
0; // Bit i aus Zeichen j holen
// der CRC-32 Algorithmus fuer ein Bit
if ((crc32_rev & 1) != bit) {
crc32_rev = (crc32_rev >>
1) ^ 0xEDB88320;
} else {
crc32_rev >>= 1;
}
mask += mask;
// Maske auf naechstes Bit setzen
}
}
return crc32_rev ^ 0xffffffff; // inverses
Ergebnis, MSB zuerst
}
int main() {
char *s = "The quick brown fox jumps over the lazy dog";
unsigned long rv = crc32(s);
printf("CRC-32 von %s ist %lx hexadeximal\n", s, rv);
return 0;
}
Programm: Festkomma Bibliothek
Der C Compiler
kennt die Datentypen short, int und long für Ganzzahlen sowie float und
double für Fließkommazahlen. Die Länge eines Automobils von 4,45m kann als
Fließkommanzahl angegeben werden. Mit einem "Trick" ist auch eine
Darstellung als Ganzzahl möglich. Wir ändern die Maßeinheit von Meter auf
Centimeter. Das Auto ist 445cm lang.
Eine Festkomma-Zahl
verallgemeinert die Idee der Werteangabe in einer passenden Einheit. Die
Automobil-Länge "445" kann als Zahl mit Komma verstanden werden. Im Programm
muß die Position des Kommas festgelegt sein. Bei der Eingabe wird der Komma
entfernt und aus der Festkomma-Zahl 4,45 wird die Ganz-Zahl 445. Bei der
Ausgabe wird das Komma an der richtigen Stelle wieder eingeführt. Eine
Festkomma-Zahl hat keinen Exponenten. Bei vielen Aufgaben ist der enorme
Wertebereich von Fließkomma-Zahlen nicht nötig.
Die Festkomma-Bibliothek arbeitet mit 15.17 Festkomma-Zahlen. 15 Bits werden
für den Ganz-Zahl Anteil benutzt und 17 Bits für den Nach-Komma Anteil. Der
Zahlenbereich reicht von -9999,99999 bis 9999,99999. Die
Festkomma-Bibliothek ist nützlich für "winzige" Computer ohne
Fliesskomma-Einheit. Häufig wird Festkomma-Rechnung bei Digitalen Signal
Prozessoren (DSP) eingesetzt. Audio- und Videodaten werden im
Festkomma-Format verarbeitet.
Die hier vorgestellte Festkomma Bibliothek ist klein an Quelltext-Zeilen,
aber schon recht umfangreich. Dank der Implementierung in C++ können
numerische Ausdrücke in der üblichen Infix-Notation geschrieben werden. Sind
die Variablen a, b zwei Festkomma-Zahlen, so addiert der Quelltext a + b die
beiden Zahlen. In gleicher Weise berechnet sqrt(a) die Quadratwurzel von
einer Festkomma-Zahl.
Der Quelltext der Festkomma Bibliothek besteht aus mehreren Teilen. Zuerst
gibt es die Umwandlungsfunktionen. Die Funktion strToFixed() wandelt einen
C-String in eine Festkomma-Zahl, die Funktion fixedToStr() wandelt von
Festkomma-Zahl nach C-String. Der zweite Teil ist der Quelltext des unified CORDIC Algorithmus. Mit
dem unified CORDIC können Festkomma-Zahlen multipliert und dividiert werden,
wenn der CORDIC Algorithmus im LINEAR Modus arbeitet. Im CIRCULAR Modus
werden trigonometrische Funktionen wie sin(), cos(), tan(), atan()
berechnet. Der HYPERBOLIC Modus liefert sinh(), cosh(), tanh(), atanh(). Die
Funktionen exp(), log(), sqrt() werden genauso schnell wie sin() vom CORDIC
Algorithmus berechnet. Neben dem grossen Vorteil von CORDIC, nämlich einem
Algorithmus für fast alle Funktionen, gibt es den Nachteil des kleinen
Konvergenzbereiches. Der CORDIC Algorithmus kann sqrt() nur für
Eingangswerte von 0,03 bis 2,42 berechnen.

Tabelle: unified CORDIC Funktionen aus 50 Years of CORDIC: Algorithms,
Architectures, and Applications
Funktion
|
konvergiert für
Eingangswerte
|
mul, div
|
-1 .. 1
|
sin, cos, tan
|
-1.74 .. 1.74
|
atan
|
-unendlich .. unendlich
|
sinh, cosh, tanh
|
-1.13 .. 1.13
|
atanh
|
-0.81 .. 0.81
|
exp
|
-1 .. 1
|
log
|
0.10 .. 9.58
|
sqrt
|
0.03 ..2.42
|
asin
|
-0.985 .. 0.985
|
asinh
|
-1.13 .. 1.13
|
Tabelle: unified CORDIC Konvergenz-Grenzen
Tabelle aus J.S. Walther: A unified
algorithm for elementary functions. Weitere Artikel über unified CORDIC
sind
Pitts Jarvis, III; 1990; A
single compact routine for computing transcendental functions; Dr.Dobb's
Journal
Ray Andraka; 1998; A
survey of CORDIC algorithms for FPGAs; ACM/SIGDA 6th international
symposium on FPGAs
Pramod K. Meher et. al.; 2009; 50 Years of CORDIC: Algorithms,
Architectures, and Applications; IEEE TRANSACTIONS ON CIRCUITS AND
SYSTEMS, Sep. 2009
Programm Test
Programm kompilieren mit
g++ -o fixedp_test fixedp_test.cpp fixedp.cpp
Das Programm starten mit
./fixedp_test
Datei
fixedp.hpp
Die Headerdatei beschreibt die Festkomma-Bibliotheks
Schnittstelle. Die C++ Klasse ist für die Operatoren wie +, -, * und /
nötig.
/* signed fixed-point */
/* mit FRACTIONBITS = 17 ist Bereich -9999.99999 .. -9999.99999 */
typedef long fixed;
enum {
FRACTIONBITS = 17, // Position Dezimalpunkt, gezaehlt von
rechts
N = 17, // Anzahl CORDIC Schleifendurchlaeufe
F = 5, // Anzahl Stellen nach Komma im Dezimalsystem
G = 5, // Anzahl Stellen vor Komma im Dezimalsystem
M = 6, // atan(2^-i), atanh(2^-i) Array Groesse
CIRCULAR = 0, // CORDIC mode
HYPERBOLIC = 1,
LINEAR = 2,
ROTATE = 0, // CORDIC flag
VECTOR = 1,
SCALE = 1 << FRACTIONBITS, // 1.0 als fixed
Zahl
};
#define FIXED(X) ((fixed)((X) * SCALE))
#define FLOAT(X) ((X) / (double)SCALE)
void cordic(int m, int f, fixed c, fixed &x, fixed &y, fixed
&z);
class fixedp {
public:
fixed f; // Festpunkt Zahl
fixedp();
fixedp(char const *s);
fixedp(fixed arg);
const char *str();
fixedp operator+(fixedp arg);
fixedp operator-(fixedp arg);
fixedp operator*(fixedp arg);
fixedp operator/(fixedp arg);
double tof();
};
fixedp sin(fixedp arg);
fixedp cos(fixedp arg);
void sincos(fixedp arg, fixedp *sinx, fixedp *cosx);
fixedp hypot(fixedp argX, fixedp argY);
fixedp atan(fixedp arg);
fixedp sinh(fixedp arg);
fixedp cosh(fixedp arg);
fixedp cathetus(fixedp argX, fixedp argY);
fixedp atanh(fixedp arg);
fixedp tan(fixedp arg);
fixedp tanh(fixedp arg);
fixedp log(fixedp arg);
fixedp exp(fixedp arg);
fixedp sqrt(fixedp arg);
fixedp asin(fixedp arg);
fixedp asinh(fixedp arg);
Datei
fixedp.cpp
Der unified CORDIC Algorithmus steht in der Funktion
cordic().
#include <stdio.h>
#include <stdlib.h>
#include "fixedp.hpp"
fixed intScale[] = {
// 10000 als fixed, 1000 als fixed, ..
0x4e200000, 0x7d00000, 0xc80000, 0x140000, 0x20000,
};
fixed fractionScale[] = {
// 0.1 als fixed, 0.01 als fixed, ...
0x3333, 0x51e, 0x83, 0xd, 0x1,
};
fixed deltaValues[][M] = {
// atan(1), atan(1/2), atan(1/4), .. als fixed
{0x1921f, 0xed63, 0x7d6d, 0x3fab, 0x1ff5, 0xffe,},
// atanh(1/2), atan(1/4), atan(1/8), .. als fixed
{0x1193e, 0x82c5, 0x4056, 0x200a, 0x1001, 0x800,}
};
fixed C1circ = 0x136e9; // 1/Circular Gain als fixed
fixed C1hyper = 0x26a43; // 1/Hyperbolic Gain als fixed
fixed C2hyper = 0xbaa4;
fixed strToFixed(const char *s) {
fixed f = 0;
int i, isNegative = 0, isFraction = 0;
for (i = 0; *s; ++s) {
if ('-' == *s) {
isNegative = 1;
} else if ('.' == *s) {
f <<=
FRACTIONBITS;
isFraction = 1;
} else if (isFraction) {
int j;
// multiplizieren durch
mehrfaches addieren
for (j = *s; j > '0';
--j) {
f +=
fractionScale[i];
}
++i;
} else {
// (f << 1) + (f
<< 3) = f * 2 + f * 8 = f * 10
f = (f << 1) + (f
<< 3) + *s - '0';
}
}
if (!isFraction) f <<= FRACTIONBITS;
if (isNegative) f = -f;
return f;
}
void fixedToStr(char *s, fixed f) {
int i, has1to9 = 0;
if (f < 0) { // Vorzeichen
f = -f;
*s++ = '-';
}
for (i = 0; i < G; ++i) { // Stellen vor Komma
int digit = '0';
while (f >= intScale[i]) {
has1to9 = 1;
++digit;
f -= intScale[i];
}
if (has1to9) *s++ = digit;
}
if (!has1to9) *s++ = '0'; // mindestens 0 vor Komma
*s++ = '.';
for (i = 0; i < F; ++i) { // Stellen nach Komma
f = (f << 1) + (f << 3); // f =
10 * f
int digit = '0';
while (f >= SCALE) {
++digit;
f -= SCALE;
}
*s++ = digit;
}
*s = '\0';
}
/* unified CORDIC algorithmus nach Walther, 1971
*
Start Delta shift sequence
* LINEAR
1.0 0, 1, 2, 3, ..
* CIRCULAR atan(1.0) 0, 1, 2, 3, ..
* HYPERBOLIC atanh(0.5) 1, 2, 3, 4, 4, 5, .. (wiederhole
3*k+1 fuer k = 1, 2, ..)
*
* m = HYPERBOLIC or LINEAR or CIRCULAR mode
* f = ROTATE or VECTOR flag
* c, x, y, z = input values
* x, y, z = output values
*/
void cordic(int m, int f, fixed c, fixed &x, fixed &y, fixed &z)
{
fixed *pDelta = deltaValues[m];
fixed delta = SCALE; // fixed 1.0
int i;
for (i = (HYPERBOLIC == m) ? 1 : 0; i < N; ++i) {
int j = (HYPERBOLIC == m && (4 == i
|| 13 == i)) ? 2 : 1;
while (--j >= 0) {
fixed xs = x >>
i;
int f1 = (f) ? y >= c :
z < c;
if (m != LINEAR) {
if (i
< M) delta = *pDelta;
fixed ys
= y >> i;
int f2 =
(CIRCULAR == m) ? f1 : 1 - f1;
x = (f2)
? x + ys : x - ys;
}
y = (f1) ? y - xs : y +
xs;
z = (f1) ? z + delta : z -
delta;
}
delta >>= 1;
++pDelta;
}
}
fixedp sin(fixedp arg) {
fixed x = C1circ, y = 0, z = arg.f;
cordic(CIRCULAR, ROTATE, 0, x, y, z);
fixedp rv;
rv.f = y;
return rv;
}
fixedp cos(fixedp arg) {
fixed x = C1circ, y = 0, z = arg.f;
cordic(CIRCULAR, ROTATE, 0, x, y, z);
fixedp rv;
rv.f = x;
return rv;
}
void sincos(fixedp arg, fixedp *sinx, fixedp *cosx) {
/* GNU libc extention to math.h */
fixed x = C1circ, y = 0, z = arg.f;
cordic(CIRCULAR, ROTATE, 0, x, y, z);
sinx->f = y;
cosx->f = x;
}
fixedp hypot(fixedp argX, fixedp argY) {
/* hypot() = sqrt(x*x + y*y) = Laenge der Hypotenuse = Vektor
Betrag */
fixed x = argX.f, y = argY.f, z = 0;
if (x < 0) x = -x; // x muss positiv sein
cordic(CIRCULAR, VECTOR, 0, x, y, z);
y = 0, z = C1circ;
cordic(LINEAR, ROTATE, 0, x, y, z);
fixedp rv;
rv.f = y;
return rv;
}
fixedp atan(fixedp arg) {
fixed x = SCALE, y = arg.f, z = 0;
cordic(CIRCULAR, VECTOR, 0, x, y, z);
fixedp rv;
rv.f = z;
return rv;
}
fixedp sinh(fixedp arg) {
fixed x = C1hyper, y = 0, z = arg.f;
cordic(HYPERBOLIC, ROTATE, 0, x, y, z);
fixedp rv;
rv.f = y;
return rv;
}
fixedp cosh(fixedp arg) {
fixed x = C1hyper, y = 0, z = arg.f;
cordic(HYPERBOLIC, ROTATE, 0, x, y, z);
fixedp rv;
rv.f = x;
return rv;
}
/* cathetus() = sqrt(x*x - y*y) = Laenge der Kathete */
fixedp cathetus(fixedp argX, fixedp argY) {
fixed x = argX.f, y = argY.f, z = 0;
if (x < 0) x = -x; // x muss positiv sein
cordic(HYPERBOLIC, VECTOR, 0, x, y, z);
y = 0, z = C1hyper;
cordic(LINEAR, ROTATE, 0, x, y, z);
fixedp rv;
rv.f = y;
return rv;
}
/* CORDIC atanh nicht 4 Quadranten geeignet */
fixedp atanh(fixedp arg) {
fixed x = SCALE, y = arg.f, z = 0;
cordic(HYPERBOLIC, VECTOR, 0, x, y, z);
fixedp rv;
rv.f = z;
return rv;
}
/* nach Walther eq. (17) */
fixedp tan(fixedp arg) {
fixed x = C1circ, y = 0, z = arg.f;
cordic(CIRCULAR, ROTATE, 0, x, y, z);
fixedp rv;
rv.f = y;
rv = rv / x;
return rv;
}
/* nach Walther eq. (18) */
fixedp tanh(fixedp arg) {
fixed x = C1circ, y = 0, z = arg.f;
cordic(HYPERBOLIC, ROTATE, 0, x, y, z);
fixedp rv;
rv.f = y;
rv = rv / x;
return rv;
}
/* nach Walther eq. (20) */
fixedp log(fixedp arg) {
fixed x = arg.f + SCALE, y = arg.f - SCALE, z = 0;
cordic(HYPERBOLIC, VECTOR, 0, x, y, z);
fixedp rv;
rv.f = z << 1; // * 2
return rv;
}
/* nach Jarvis Example 4d */
fixedp exp(fixedp arg) {
fixed x = C1hyper, y = C1hyper, z = arg.f;
cordic(HYPERBOLIC, ROTATE, 0, x, y, z);
fixedp rv;
rv.f = x;
return rv;
}
/* nach Jarvis Example 4e */
fixedp sqrt(fixedp arg) {
fixed x = arg.f + C2hyper, y = arg.f - C2hyper, z = 0;
cordic(HYPERBOLIC, VECTOR, 0, x, y, z);
fixedp rv;
rv.f = x;
return rv;
}
/* nach Andraka ch. 3.8 */
fixedp asin(fixedp arg) {
fixed x = C1circ, y = 0, z = 0;
cordic(CIRCULAR, VECTOR, -arg.f, x, y, z);
fixedp rv;
rv.f = z;
return rv;
}
/* nach Andraka ch. 3.8 */
fixedp asinh(fixedp arg) {
fixed x = C1hyper, y = 0, z = 0;
cordic(HYPERBOLIC, VECTOR, -arg.f, x, y, z);
fixedp rv;
rv.f = z;
return rv;
}
/* Constructors: */
fixedp::fixedp() {
f = 0;
};
fixedp::fixedp(char const *s) {
f = strToFixed(s);
}
fixedp::fixedp(fixed arg) {
f = arg;
}
const char *fixedp::str() {
static char t[16][20];
static int ndx;
ndx = (++ndx) & 15;
fixedToStr(&t[ndx][0], f);
return t[ndx];
}
fixedp fixedp::operator+(fixedp arg) {
fixedp rv;
rv.f = f + arg.f;
return rv;
}
fixedp fixedp::operator-(fixedp arg) {
fixedp rv;
rv.f = f - arg.f;
return rv;
}
fixedp fixedp::operator*(fixedp arg) {
fixed x = f, y = 0, z = arg.f;
cordic(LINEAR, ROTATE, 0, x, y, z);
fixedp rv;
rv.f = y;
return rv;
}
fixedp fixedp::operator/(fixedp arg) {
fixed x = arg.f, y = f, z = 0;
if (x < 0) {
x = -x; // x muss positiv sein
y = -y; // deshalb Vorzeichenwechsel
}
cordic(LINEAR, VECTOR, 0, x, y, z);
fixedp rv;
rv.f = z;
return rv;
}
double fixedp::tof() {
return FLOAT(f);
}
Datei
fixedp_test.cpp
Die Festkomma Bibliothek wird mit dieser Datei getestet.
In der Programmausgabe steht das Ergebnis der Festkomma-Bibliothek neben dem
entsprechenden Ergebnis der Fließkomma-Bibliothek. Die Funktion cordicInit()
erzeugt die Konstanten für die ASCII nach Festkomma-Umwandlung und den
CORDIC Algorithmus. Die Funktion cordicInit() ist auf der Zielmaschine nicht
nötig. Diese Funktion zeigt das Henne-Ei Problem: Es werden
Fließkomma-Berechnungen wie atan() benötigt um die Konstanten zu bestimmen
für die Festkomma-Bibliothek mit ihrer atan() Funktion.
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include "fixedp.hpp"
extern fixed intScale[];
extern fixed fractionScale[];
extern fixed deltaValues[][M];
extern fixed C1circ;
extern fixed C1hyper;
extern fixed C2hyper;
void cordicInit() {
int i;
double arg;
printf("static fixed intScale[] = {\n");
long factor = 1;
for (i = 0; i < G - 1; ++i) factor *= 10;
for (i = 0; i < G; ++i) {
intScale[i] = factor * SCALE;
factor /= 10;
printf("0x%x, ", intScale[i]);
}
printf("};\n");
printf("static fixed fractionScale[] = {\n");
factor = 10;
for (i = 0; i < F; ++i) {
fractionScale[i] = SCALE / factor;
factor *= 10;
printf("0x%x, ", fractionScale[i]);
}
printf("};\n");
printf("static fixed deltaValues[][M] = {\n{");
for (i = 0, arg = 1.0; i < M; ++i, arg /= 2.0) {
deltaValues[CIRCULAR][i] =
FIXED(atan(arg));
printf("0x%x, ",
deltaValues[CIRCULAR][i]);
}
printf("},\n{");
for (i = 0, arg = 0.5; i < M; ++i, arg /= 2.0) {
deltaValues[HYPERBOLIC][i] =
FIXED(atanh(arg));
printf("0x%x, ",
deltaValues[HYPERBOLIC][i]);
}
printf("}};\n");
/* Bestimme CORDIC Gains */
fixed x = SCALE, y = 0, z = 0;
cordic(CIRCULAR, ROTATE, 0, x, y, z);
C1circ = FIXED(1.0 / FLOAT(x));
x = SCALE, y = 0, z = 0;
cordic(HYPERBOLIC, ROTATE, 0, x, y, z);
C1hyper = FIXED(1.0 / FLOAT(x));
C2hyper = FIXED((FLOAT(C1hyper) / 2.0) * (FLOAT(C1hyper) /
2.0));
printf("static fixed C1circ = 0x%x;\n", C1circ);
printf("static fixed C1hyper = 0x%x;\n", C1hyper);
printf("static fixed C2hyper = 0x%x;\n", C2hyper);
}
int main() {
cordicInit();
fixedp x = "0.123";
fixedp y("0.456");
printf("(0.123) %s = x, (0.456) %s = y\n", x.str(),
y.str());
printf("\n+, - and CORDIC functions:\n");
char const *xArgs[] = {"0.3", "-0.3"};
char const *yArgs[] = {"0.2", "-0.2"};
fixedp f;
int i, j;
for (i = 0; i < 2; ++i) {
for (j = 0; j < 2; ++j) {
x = xArgs[i];
y = yArgs[j];
f = x + y;
printf("%s = %s + %s\n",
f.str(), x.str(), y.str());
f = x - y;
printf("%s = %s - %s\n",
f.str(), x.str(), y.str());
f = x * y;
printf("%s = %s * %s\n",
f.str(), x.str(), y.str());
f = x / y;
printf("%s = %s / %s\n",
f.str(), x.str(), y.str());
}
}
double ff; // nur zum Vergleich
x = "-1.5708", f = sin(x), ff = sin(x.tof());
printf("(%1.5f) %s = sin(%s)\n", ff, f.str(), x.str());
x = "1.5708", f = sin(x), ff = sin(x.tof());
printf("(%1.5f) %s = sin(%s)\n", ff, f.str(), x.str());
x = "-1.5708", f = cos(x), ff = cos(x.tof());
printf("(%1.5f) %s = cos(%s)\n", ff, f.str(), x.str());
x = "1.5708", f = cos(x), ff = cos(x.tof());
printf("(%1.5f) %s = cos(%s)\n", ff, f.str(), x.str());
x = "-9000", f = atan(x), ff = atan(x.tof());
printf("(%1.5f) %s = atan(%s)\n", ff, f.str(), x.str());
x = "9000", f = atan(x), ff = atan(x.tof());
printf("(%1.5f) %s = atan(%s)\n", ff, f.str(), x.str());
x = "-1.0", f = sinh(x), ff = sinh(x.tof());
printf("(%1.5f) %s = sinh(%s)\n", ff, f.str(), x.str());
x = "1.0", f = sinh(x), ff = sinh(x.tof());
printf("(%1.5f) %s = sinh(%s)\n", ff, f.str(), x.str());
x = "-1.0", f = cosh(x), ff = cosh(x.tof());
printf("(%1.5f) %s = cosh(%s)\n", ff, f.str(), x.str());
x = "1.0", f = cosh(x), ff = cosh(x.tof());
printf("(%1.5f) %s = cosh(%s)\n", ff, f.str(), x.str());
x = "-0.806", f = atanh(x), ff = atanh(x.tof());
printf("(%1.5f) %s = atanh(%s)\n", ff, f.str(), x.str());
x = "0.806", f = atanh(x), ff = atanh(x.tof());
printf("(%1.5f) %s = atanh(%s)\n", ff, f.str(), x.str());
x = "0.3", y = "0.4", f = hypot(x, y);
printf("(0.5) %s = hypot(%s, %s)\n", f.str(), x.str(),
y.str());
x = "-0.3", y = "0.4", f = hypot(x, y);
printf("(0.5) %s = hypot(%s, %s)\n", f.str(), x.str(),
y.str());
x = "0.3", y = "-0.4", f = hypot(x, y);
printf("(0.5) %s = hypot(%s, %s)\n", f.str(), x.str(),
y.str());
x = "-0.3", y = "-0.4", f = hypot(x, y);
printf("(0.5) %s = hypot(%s, %s)\n", f.str(), x.str(),
y.str());
x = "0.5", y = "0.4", f = cathetus(x, y);
printf("(0.3) %s = cathetus(%s, %s)\n", f.str(), x.str(),
y.str());
x = "-0.5", y = "0.4", f = cathetus(x, y);
printf("(0.3) %s = cathetus(%s, %s)\n", f.str(), x.str(),
y.str());
x = "0.5", y = "-0.4", f = cathetus(x, y);
printf("(0.3) %s = cathetus(%s, %s)\n", f.str(), x.str(),
y.str());
x = "-0.5", y = "-0.4", f = cathetus(x, y);
printf("(0.3) %s = cathetus(%s, %s)\n", f.str(), x.str(),
y.str());
printf("\nadditional functions:\n");
x = "-1.5", f = tan(x), ff = tan(x.tof());
printf("(%1.5f) %s = tan(%s)\n", ff, f.str(), x.str());
x = "1.5", f = tan(x), ff = tan(x.tof());
printf("(%1.5f) %s = tan(%s)\n", ff, f.str(), x.str());
x = "-1.1", f = tanh(x), ff = tanh(x.tof());
printf("(%1.5f) %s = tanh(%s)\n", ff, f.str(), x.str());
x = "1.1", f = tanh(x), ff = tanh(x.tof());
printf("(%1.5f) %s = tanh(%s)\n", ff, f.str(), x.str());
x = "0.1097", f = log(x), ff = log(x.tof());
printf("(%1.5f) %s = log(%s)\n", ff, f.str(), x.str());
x = "9.1", f = log(x), ff = log(x.tof());
printf("(%1.5f) %s = log(%s)\n", ff, f.str(), x.str());
x = "-1.05", f = exp(x), ff = exp(x.tof());
printf("(%1.5f) %s = exp(%s)\n", ff, f.str(), x.str());
x = "0.1", f = exp(x), ff = exp(x.tof());
printf("(%1.5f) %s = exp(%s)\n", ff, f.str(), x.str());
x = "0.05", f = sqrt(x), ff = sqrt(x.tof());
printf("(%1.5f) %s = sqrt(%s)\n", ff, f.str(), x.str());
x = "2.7", f = sqrt(x), ff = sqrt(x.tof());
printf("(%1.5f) %s = sqrt(%s)\n", ff, f.str(), x.str());
x = "-0.985", f = asin(x), ff = asin(x.tof());
printf("(%1.5f) %s = asin(%s)\n", ff, f.str(), x.str());
x = "0.985", f = asin(x), ff = asin(x.tof());
printf("(%1.5f) %s = asin(%s)\n", ff, f.str(), x.str());
x = "-1.14457257", f = asinh(x), ff = asinh(x.tof());
printf("(%1.5f) %s = asinh(%s)\n", ff, f.str(), x.str());
x = "1.14457257", f = asinh(x), ff = asinh(x.tof());
printf("(%1.5f) %s = asinh(%s)\n", ff, f.str(), x.str());
return 0;
}
Vorbereitung serielle Schnittstelle (V.24,
RS232)
Vor der Programmierung wird mit Hilfe von UNIX Kommandos der
Hardware Aufbau getestet. Für eine Kommunikation über serielle Schnittstelle
zwischen zwei Computern (DTE Geräten)
- muß ein Null-Modem Kabel verwendet werden
- müssen beide serielle Schnittstellen auf die gleiche Geschwindigkeit,
Parität, usw. gestellt werden
Die Einstellung auf 9600 bit/s, 8 Data bits, odd parity, 1 Stop bit
erfolgt mit
stty -F /dev/ttyS0 9600 cs8 -cstopb parenb parodd -ignpar inpck raw -echo
clocal -crtscts
Die Parameter im Detail:
| -F /dev/ttyS0 |
Gerätespezialdatei, hier COM1 Schnittstelle |
| 9600 cs8 -cstopb |
9600 bit/s, 8 Datenbit, 1 Stopbit (-cstopb bedeutet nicht 2
Stopbits) |
| parenb parodd |
Ungerade Parität |
| -ignpar inpck |
Parität bei Eingangsdaten prüfen (-ignpar bedeutet nicht
ignorieren) |
| raw |
Zeichen werden transparent (ohne Ersetzungen) übertragen |
| -echo |
Empfangene Zeichen werden nicht wieder zurückgesendet |
| clocal |
Hardware-Handshake Signale DCD, DSR werden ignoriert |
| -crtscts |
Hardware-Handshake Signal CTS wird ignoriert |
Test
der seriellen Schnittstelle mit UNIX Kommandos
Am ersten Rechner
eingeben
stty -F /dev/ttyS0 9600 cs8 -cstopb parenb parodd -ignpar inpck raw -echo
clocal -crtscts
cat </dev/ttyS0
Am zweiten Rechner eingeben
stty -F /dev/ttyS0 9600 cs8 -cstopb parenb parodd -ignpar inpck raw -echo
clocal -crtscts
echo Hallo >/dev/ttyS0
Programm: Serielle Schnittstelle senden
Die UNIX
system-calls für I/O (Input/Output, Ein-/Ausgabe) sind
- open() zum Öffnen der Schnittstelle
- read() zum Lesen von Bytes von der
Schnittstelle
- write() zum Schreiben von Bytes auf die
Schnittstelle
- close() zum Schließen der Schnittstelle
Linux Besonderheiten:
- Bei der seriellen Schnittstelle immer nur 1 Byte lesen oder
schreiben
- Die Tastatur-Schnittstelle arbeitet gepuffert (Zeichen werden erst bei
<RETURN> übertragen. Für nicht gepufferte Tastatur-Schnittstelle das
Kommando benutzen:
stty -F /dev/tty -icanon
Das Programm führt eine Endlosschleife aus. Hole ein Zeichen von der
Tastatur (dem stdin Gerät) und schreibe es auf die Schnittstelle.
Programm Test
Programm kompilieren mit
gcc -Wall -o seriell_send seriell_send.c
Am ersten Rechner eingeben
cat </dev/ttyS0
Am zweiten Rechner eingeben
./seriell_send
Datei
seriell_send.c
#include
<stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd = open("/dev/ttyS0", O_RDWR);
if (fd < 0) {
// Fehler bei open()
perror("seriell_send open");
exit(1);
}
for(;;)
{
// Endlosschleife
char buf[1];
int bytes = read(STDIN_FILENO, buf, sizeof
buf);
// ein Zeichen von Tastatur holen
write(fd, buf, bytes); //
ein Byte an serielle Schnittstelle ausgeben
}
// hierher kommt das Programm nie
return 0;
}
Übung
Schreiben Sie ein Programm seriell_recv
welches Zeichen von der seriellen Schnittstelle liest und auf dem Bildschirm
ausgibt. Testen Sie das Programm mit:
Am ersten Rechner eingeben
./seriell_recv
Am zweiten Rechner eingeben
./seriell_send
Programm: Multi-IO mit select()
Für Duplex Betrieb
(gleichzeitig senden und empfangen) sind seriell_send und seriell_recv nicht
geeignet. Die system-calls read() oder getchar() blockieren (warten bis
Daten vorhanden sind). Eine Lösung für das "mehrere Dinge gleichzeitig tun"
Problem ist select(), der system-call für Ein-Ausgabe Multiplexing.
Dem select() wird eine Liste von file-descriptors übergeben. Das
Betriebssystem beendet den select() call wenn Daten für mindestens einen der
file-descriptors vorliegen.
Programm Test
Programm kompilieren mit
gcc -Wall -o multi_io multi_io.c
Am ersten Rechner eingeben
./multi_io
Am zweiten Rechner eingeben
./multi_io
Testen Sie auch das unterschiedliche Verhalten bei -icanon und icanon.
Welche Betriebsart finden Sie für ein Kommunikations-Programm
angenehmer?
Datei
multi_io.c
#include
<stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/select.h>
int main() {
int fdCom1 = open("/dev/ttyS0", O_RDWR);
if (fdCom1 < 0)
{
// Fehler bei open()
perror("multi_io COM1");
exit(1);
}
for(;;) {
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(fdCom1, &readfds);
FD_SET(STDIN_FILENO, &readfds);
int rv = select(32, &readfds, NULL, NULL, NULL);
if (-1 == rv) {
perror("multi_io select");
exit(1);
}
if (rv > 0) {
if (FD_ISSET(STDIN_FILENO, &readfds)) {
// Daten vom Keyboard verfuegbar
char buf[1];
int bytes = read(STDIN_FILENO,
buf, sizeof buf);
write(fdCom1, buf,
bytes); //
auf RS232 ausgeben
}
if (FD_ISSET(fdCom1, &readfds))
{ // Daten von der RS232 verfuegbar
char buf[1];
int bytes = read(fdCom1, buf,
sizeof buf);
write(STDOUT_FILENO, buf,
bytes); // auf xterm Fenster ausgeben
}
}
}
return 0;
}
Übung
Ändern Sie das Programm multi_io.c zu
multi_io1.c. Der buf für den read() system-call soll 40 Bytes groß werden.
Testen Sie das Programm mit Eingaben die weniger und auch die mehr als 40
Byte enthalten. In beiden Fällen soll multi_io1.c so wie multi_io.c
funktionieren.
Tipp: Sie müssen nur zwei konstante Zahlen ändern.
Vorbereitung TCP Kommunikation
Das Programm multi_io
konnten wir in beiden Endgeräten benutzen. Bei TCP Kommunikation ist ein
Endgerät der TCP Client, das andere Endgerät der TCP Server. Ein Webbrowser
wie Firefox ist ein TCP Client welcher das HTTP Protokoll verwendet.
Der TCP Client muss über den TCP Server zwei Parameter wissen:
Der TCP Server muss nur einen Parameter wissen:
- Port-Nummer (well known port number)
Der TCP Server arbeitet nach dem Prinzip "sende zurück an Absender".
Die nötige Absender Information ist Teil jedes TCP Datenpaketes welches
folgende Adressinformation enthält:
- Source (Absender) IP, Source Port-Nummer
- Destination (Empfänger) IP, Destination Port-Nummer
Die IP Adresse kann direkt angegeben werden als 10.111.26.61 oder kann
als Name (z.B. eddfl1a) in der Datei /etc/hosts nachgesehen werden oder kann
über DNS (Domain Name System) von einem DNS-Server Computer geholt
werden (z.B. im Internet www.google.de).
Die Port-Nummer kann direkt angegeben werden (z.B. 80) oder kann als Name
(z.B. http) in der Datei /etc/services nachgesehen werden oder kann über den
Portmapper Dienst von anderen Computern geholt werden.
Die Port-Nummern von 0 bis 1023 sind "superuser" Port-Nummern. Für eigene
Programme empfiehlt sich Port-Nummern aus dem Bereich 49152 bis 65535 zu
benutzen. Diese sind "private" Port-Nummern. Dazwischen liegen die "well
known Port-Nummern", z.B. 5060 für den SIP Port von Voice-over-IP.
TCP
Test mit UNIX Kommandos
Das Programm netcat kann die Rolle eines TCP
Clients oder eines TCP Servers übernehmen. Eventuell müssen Sie netcat noch
mit YAST o.ä. installieren.
Im ersten xterm Fenster eingeben für TCP-Server:
netcat -l -p 55555
Im zweiten xterm Fenster eingeben für TCP-Client
netcat 127.0.0.1 55555
Übung
Benutzen Sie netcat zwischen zwei Computern.
Welche Parameter müssen gegenseitig bekannt sein? Schreiben Sie Ihre
well-known IP-Adresse nach /etc/hosts und ihre well-known Port-Nummer nach
/etc/services und arbeiten Sie mit Namen anstelle von Nummern. Funktioniert
die Datenübertragung duplex? Wie reagiert netcat auf -icanon?
Programm: TCP client
Eine prima Einführung in die
TCP Programmierung unter C ist "Beej's Guide to Network Programming" auf
http://beej.us/guide/bgnet
Der open() in multi_io.c wird geändert für die TCP Kommunikation. Die
verschiedenen TCP Parameter werden mit mehreren system-calls mitgeteilt.
Diese TCP client Start Sequenz ist immer gleich. Sie besteht aus:
- gethostbyname() IP-Adresse des TCP Server holen
-
socket()
Socket-descriptor (file-descriptor) holen
-
connect()
Verbindung zum TCP-Server aufbauen
Network Byte Order
Ein kleines aber wichtiges
Detail bei der Behandlung von Port-Nummern und IP-Adressen ist die Network
Byte Order. Die Integer Werte im IP oder TCP Header müssen in Network Byte
Order oder Big Endian angegeben werden. Die Intel CPU arbeitet mit Little
Endian. Es gibt folgende Funktionen zum Umwandlung von Host Byte Order
(Integer Darstellung der CPU) nach Network Byte Order:
| htons() |
Host Byte Order nach Network Byte Order Port Nummer (16bit) |
| htonl() |
Host Byte Order nach Network Byte Order IPv4 Adresse (32bit) |
| ntohs() |
Network Byte Order nach Host Byte Order Port Nummer (16bit) |
| ntohl() |
Network Byte Order nach Host Byte Order IPv4 Adresse (32bit) |
Programm Test
Programm kompilieren mit
gcc -Wall -o tcp_client tcp_client.c
Im ersten xterm Fenster eingeben für TCP-Server:
netcat -l -p 55555
Im zweiten xterm Fenster eingeben für TCP-Client
./tcp_client localhost
Datei
tcp_client.c
#include
<stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <netdb.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#define PORT 55555
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "tcp_client usage: tcp_client
hostname\n");
exit(1);
}
struct hostent *he;
he = gethostbyname(argv[1]); // Name nach IP
Adresse umsetzen
if (NULL == he) {
perror("tcp_client gethostbyname");
exit(1);
}
int fdServer = socket(AF_INET, SOCK_STREAM, 0);
if (-1 == fdServer) {
perror("tcp_client socket");
exit(1);
}
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof
serv_addr); // mit 0 initialisieren
serv_addr.sin_family =
AF_INET;
// IPv4 Protokoll
serv_addr.sin_addr = *((struct in_addr *) he->h_addr);
serv_addr.sin_port = htons(PORT);
// PORT in Network Byte Order bringen
int rv = connect(fdServer, (struct sockaddr *)&serv_addr, sizeof
serv_addr);
if (-1 == rv) {
perror("tcp_client connect");
exit(1);
}
for(;;) {
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(fdServer, &readfds);
FD_SET(STDIN_FILENO, &readfds);
int rv = select(32, &readfds, NULL, NULL, NULL);
if (-1 == rv) {
perror("tcp_client select");
exit(1);
}
if (rv > 0) {
if (FD_ISSET(STDIN_FILENO, &readfds)) {
// Daten vom Keyboard verfuegbar
char buf[1];
int bytes = read(STDIN_FILENO,
buf, sizeof buf);
write(fdServer, buf,
bytes); // auf das
Netzwerk ausgeben
}
if (FD_ISSET(fdServer, &readfds))
{ // Daten vom Netzwerk verfuegbar
char buf[1];
int bytes = read(fdServer, buf,
sizeof buf);
if (bytes <= 0) {
// Verbindung von
Gegenseite geschlossen oder Fehler
close(fdServer);
exit(1);
}
write(STDOUT_FILENO, buf,
bytes); // auf xterm Fenster ausgeben
}
}
}
return 0;
}
Übung
1
Entfernen Sie htons(), d.h. aus
serv_addr.sin_port = htons(PORT);
wird
serv_addr.sin_port = PORT;
und testen Sie das Programm. Funktioniert es noch?
Übung
2
Ändern Sie das Programm zu tcp_client1.c. Die Portnummer soll nicht
mehr als Konstante festgelegt sein sondern als zweiter Parameter beim
Programmstart angegeben werden.
Aus "tcp_client localhost" wird "tcp_client1 localhost 55555".
Übung
3
Ändern Sie das Programm tcp_client1.c zu tcp_client2.c. Der buf für
den read() system-call soll 40 Bytes groß werden. Testen Sie das
Programm mit TCP Datenpaketen die weniger und auch die mehr als 40 Byte
enthalten. In beiden Fällen soll tcp_client2.c so wie tcp_client1.c
funktionieren.
Tipp: Sehen Sie bei mult_io1.c nach.
Übung
4
Der system-call
connect() ist ein
"slow system-call". Wie lange dauert
ein connect() wenn der TCP-Server
Computer ausgeschaltet ist (z.B. eigene IP=192.168.0.1, nicht vorhandener
Computer=192.168.0.99)? Ändern Sie das Programm tcp_client2.c zu
tcp_client3.c. Setzen Sie vor und nach dem connect()
system-call
einen time()
system-call. Geben Sie die
Zeitdifferenz in Sekunden der beiden time()
system-calls aus. Vergleichen Sie
ihr Ergebnis mit
time./tcp_client3 192.168.0.99
55555
Dabei ist 192.168.0.99 die IP Adresse des TCP-Servers auf einem nicht
vorhandenen Computer.
Übung
5
Anstelle von read() kann bei TCP Verbindungen auch recv() verwendet
werden. Anstelle von write() funktioniert auch send(). Der vierte Parameter
von recv() und send() ist dabei 0, wenn nur das read() und write() Verhalten
gewünscht wird. Ersetzen Sie die system-calls und prüfen Sie ob das Programm
sich wie zuvor verhält.
Programm: TCP server für nur einen TCP client
Das
erste TCP server Programm kann nur mit einem TCP client gleichzeitig eine
Verbindung unterhalten. Aber auch für diesen einfachen Fall muss die TCP
Server Start Sequenz durchlaufen werden.
- socket() Socket-Descriptor (file-descriptor)
holen
- bind() Socket-Descriptor mit TCP-Server
IP-Adresse und Port-Nummer verbinden
- listen() Socket als "LISTEN" Socket
konfigurieren zur Verbindung-Annahme
- accept() Auf Verbindung-Aufbau Meldungen von
TCP-Clients warten
Programm Test
Programm kompilieren mit
gcc -Wall -o tcp_server tcp_server.c
Im ersten xterm Fenster eingeben für TCP-Server:
./tcp_server
Im zweiten xterm Fenster eingeben für TCP-Client
./tcp_client localhost
Datei
tcp_server.c
#include
<stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#define PORT 55555
// Funktion fuer TCP Client Kommunikations Schleife
int do_client(int fdKbd, int fdClient) {
for(;;) {
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(fdClient, &readfds);
FD_SET(fdKbd, &readfds);
int rv = select(32, &readfds, NULL, NULL, NULL);
if (-1 == rv) {
perror("tcp_server select");
exit(1);
}
if (rv > 0) {
if (FD_ISSET(STDIN_FILENO, &readfds))
{
char buf[1];
int bytes = read(STDIN_FILENO,
buf, sizeof buf);
write(fdClient, buf, bytes);
}
if (FD_ISSET(fdClient, &readfds)) {
char buf[1];
int bytes = read(fdClient, buf,
sizeof buf);
if (bytes <= 0) {
close(fdClient);
return -1;
}
write(STDOUT_FILENO, buf,
bytes);
}
}
}
return 0;
}
int main() {
int fdListen = socket(AF_INET, SOCK_STREAM, 0);
if (-1 == fdListen) {
perror("tcp_server socket");
exit(1);
}
int val = 1;
int rv = setsockopt(fdListen, SOL_SOCKET, SO_REUSEADDR, &val,
sizeof val);
if (-1 == rv) {
perror("tcp_server setsockopt");
exit(1);
}
struct sockaddr_in
my_addr; // TCP
Server IP Informationen
memset(&my_addr, 0, sizeof my_addr);
my_addr.sin_family = AF_INET;
my_addr.sin_addr.s_addr = INADDR_ANY; // bedeutet TCP-Server IP
Adresse
my_addr.sin_port = htons(PORT);
// PORT in Network Byte Order bringen
rv = bind(fdListen, (struct sockaddr *) &my_addr, sizeof
my_addr);
if (-1 == rv) {
perror("tcp_server bind");
exit(1);
}
rv = listen(fdListen, 5);
if (-1 == rv) {
perror("tcp_server listen");
exit(1);
}
for(;;) {
struct sockaddr_in addr;
// TCP Client IP
Informationen
socklen_t addrlen = sizeof addr;
int fdClient = accept(fdListen, (struct sockaddr
*)&addr, &addrlen);
if (-1 == fdClient) {
perror("tcp_server accept");
continue;
}
printf("tcp_server connected from %s\n",
inet_ntoa(addr.sin_addr));
do_client(STDIN_FILENO, fdClient);
printf("tcp_server closed from %s\n",
inet_ntoa(addr.sin_addr));
}
return 0;
}
Übung
1
Benutzen Sie tcp_server zusammen mit zwei tcp_client Programmen. Was
passiert genau wenn das zweite tcp_client Programm gestartet wird, während
das erste noch läuft? Nachdem das erste tcp_client Programm beendet
wird?
Übung
2
Bringen Sie die Änderungen von tcp_client1.c in die neue TCP Server
Version tcp_server1.c. Die Port-Nummer soll als Kommandozeilenparameter
übergeben werden.
Übung
3
Bringen Sie die Änderungen von tcp_client2.c in die neue TCP Server
Version tcp_server2.c. Die buf Variable in do_client() soll 40 Bytes fassen.
Testen Sie mit Eingaben die länger als 40 Zeichen sind.
Zeiger/Größe mit Länge als
Ein-/Ausgabeparameter
Der Zeiger/Größe Doppel-Parameter kann noch weiter
entwickelt werden. Bei der Socket-Schnittstelle (die
C-Bibliotheks-Funktionen welche die TCP Schnittstelle realisieren) gibt es
bei einigen Funktionen den Längen Parameter als Eingabeparameter (von
aufrufende Funktion an aufgerufene Funktion) und als Ausgabeparameter (von
aufgerufener Funktion zu aufrufender Funktion). In C wird ein
Ausgabeparameter als Zeiger-Variable realisiert. Aus einem Größenparameter
für Eingabe
int n
wird als Längenparameter für Ein-/Ausgabe
int *n
Im Beispiel aus tcp_server.c:
struct sockaddr_in
addr; // TCP
Client IP Informationen
socklen_t addrlen = sizeof addr;
int fdClient = accept(fdListen, (struct sockaddr
*)&addr, &addrlen);
ist der Zeiger die Variable addr und die Länge als In/Out Parameter ist
addrlen.
Übung
1
int reuseaddr = 0;
unsigned len = sizeof reuseaddr;
rv = getsockopt(fdListen, SOL_SOCKET, SO_REUSEADDR, &reuseaddr,
&len);
printf("SO_REUSEADDR = %d\n", reuseaddr);
Bauen Sie das obige Stück Quelltext nach dem setsockopt() system-call in
tcp_server.c ein. Die geänderte Datei soll tcp_servera.c heißen. Testen Sie
ob tcp_servera sich so verhält wie tcp_server.
Übung
2
Geben Sie den Inhalt der Variablen len direkt vor und nach dem Aufruf
von getsockopt() aus.
TCP
und Serialization
Serialization (Marshalling, Serialisieren) bedeutet
strukturierte Daten (z.B. die Datensätze einer Datenbank) so in eine
unstrukturierte äußere Form (z.B. eine Datei auf der Festplatte) zu bringen,
das später die strukturierten Daten wieder zurückgewonnen werden können (die
Datensätze der Datenbank). Bei der Übertragung von Datensätzen über TCP
müssen die Datensätze serialisiert werden.
Das TCP Protokoll ist ein Stream Protokoll. Damit passt TCP gut zu den UNIX
Ein-/Ausgabe Streams (fopen(), fputs(), fgets(), ...). Wenn verschiedene
einzelne Datensätze in einem Datenstrom transportiert werden muss der
Daten-Empfänger den Datenstrom wieder in einzelne Datensätze zurück wandeln
können. Ein Datenfehler in einem Datensatz darf nur diesen Datensatz
unbrauchbar machen - der Fehler darf nicht dazu führen das alle folgenden
korrekten Datensätze nicht mehr vom Datenstrom in Datensätze zurück
gewandelt werden können.
Im Datenstrom werden zwischen den einzelnen Datensätzen Delimiter
(Separatoren, Abgrenzer, Trennzeichen) eingefügt.
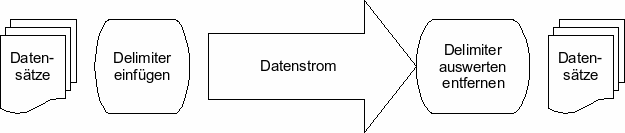
Die Delimiter müssen im Datenstrom immer sicher erkannt werden. Es gibt
mehrere Lösungen:
- Als Delimiter Zeichen wird ein Zeichen verwendet welches nicht im
Datensatz auftaucht bzw. im Datensatz schon als Delimiter Zeichen
verwendet wird. Werden die Daten in ASCII Kodierung übertragen sind die
ASCII Zeichen FS (file separator), GS (group separator), RS (record
separator) und US (unit separator) als Delimiter vorgesehen. Üblich ist
aber auch LF (line feed) als Delimiter.
- Vor dem eigentlichen Datensatz wird die Datensatz-Länge übertragen.
Der Empfänger liest zuerst die Datensatz-Länge und kann dann den Datensatz
aus dem Datenstrom lesen. Diese length/data Kodierung ist sehr empfindlich
gegen Fehler. Ist eine einzige Datensatz-Länge falsch (z.B.
Datensatz-Länge = 999, echte Länge des Datensatzes = 1000) werden alle
folgenden Datensätze falsch aus dem Datenstrom gelesen!
- Mit Byte Stuffing oder mit Transportkodierung wird die length/data
Kodierung robust. Eine bekannte Transportkodierung ist Base64, welche zur
Übertragung von Binärdatenals E-Mail Anhang benutzt wird. Eine Base128
Transportkodierung ist möglich wenn der Transportkanal 8 Bit Datenwerte
übertragen kann.
- Die Datensätze werden in einzelnen TCP-Paketen übertragen (TCP ist ein
stream-Protokoll, aber die Funktionen send() und recv() arbeiten
block-weise). Damit das Betriebssystem nicht die Daten von mehreren send()
Aufrufen in einem TCP Paket unterbringt wird die Socket-Option TCP_NODELAY
benutzt um den "Nagle algorithm" auszuschalten. Zwischen Sender und
Empfänger muss eine maximale Datensatz-Größe festgelegt werden. Diese
sollte kleiner gleich der MTU (Maximal Transfer Unit) sein. Für TCP auf
Ethernet sollte Datensatz-Größe kleiner gleich 1400 Bytes gewählt
werden.
- IP fragmentation ist eine Fähigkeit von IP welche dazu führt das aus
einem send() Aufruf im Empfänger mehrere recv() Aufrufe werden. Deshalb
sollte die length/data Kodierung mit der TCP_NODELAY Datenpaket
Übertragung kombiniert werden. Auch hier ist eine maximale Datensatz-Größe
nötig. Diese kann größer als 1400 Bytes sein. Sie muss aber kleiner gleich
65535 Bytes (16Bit Size Feld im TCP Header) sein.
Für die Serialization gibt es für C die tpl Bibliothek: http://tpl.sourceforge.net/
Für C++ bietet sich Boost an: http://www.boost.org/libs/serialization/doc/index.html
Byte
Stuffing
In der Datenübertragung muss man zwischen Nutzdaten und
Steuersymbolen unterscheiden. Im ASCII Zeichensatz werden die Steuersymbole
Communication Control genannt. Im Token Ring Protokoll IEEE 802.5 gibt neben
den Nutzdaten (8 Bit = 256 Zeichen) noch das Steuersymbol "Starting
Delimiter" SD. Token Ring benutzt die Manchester Kodierung. Bei dieser
Kodierung wird jedes übertragene Bit aus zwei Signalen gebildet. Neben den
Bit-Werten 0 und 1 gibt es noch die Bit-Werte J und K. Der SD besteht aus
dem Bitmuster JK0JK000. Dieses besondere Signalmuster wird von der
Empfänger-Hardware erkannt. Der Token Ring arbeitet mit 257 Zeichen, 256
Nutzdatenzeichen und dem Steuersymbol SD.
Ein TCP Stream kennt nur 256 verschiedene Zeichen, deshalb wird für
Steuersymbole Byte Stuffing eingesetzt. Einem C-Programmierer ist Byte
Stuffing als Escape Sequenz bekannt. Um in einem C-String das "Newline"
Zeichen abzulegen wird "\n" geschrieben. Für das \ Zeichen selbst wird "\\"
geschrieben. Die String-Länge von "\\" ist 1. Als Byte Stuffing Escape
Zeichen ist im ASCII Standard das Steuerzeichen DLE (Data Link Escape, 0x10)
vorgesehen.
Eine transparente ASCII Datenübertragung benutzt folgende Kodierung der
ASCII Communication Control Zeichen:
Zeichen
|
nach Byte Stuffing
|
Bedeutung
|
0x10
|
0x10 0x10
|
das Escape Zeichen selbst.
|
SOH
|
0x10 0x01
|
Start of Heading oder Starting
Delimiter. Mit diesem Steuersymbol beginnt das Byte Stuffing
Datenpaket.
|
Eine robuste length/data Kodierung mit Byte Stuffing benutzt "0x10 0x01" als
Starting Delimiter. Nach dem SD folgt die Byte-Stuffed(!) Länge in z.B. 2
Bytes. Die Länge sollte in Network Byte Order übertragen werden. Die
Byte-Stuffed Länge ist allgemein größer als die Datenpaketlänge, weil jedes
Auftreten von 0x10 im Datenpaket als 0x10 0x10 übertragen wird. Die Funktion
bytestuff(char *out, int outsize, const char *in, const int inlen) führt
Byte Stuffing auf den binären String in aus. Der Byte-Stuffed String steht
in out und hat die maximale Länge outsize. Der Returnwert von bytestuff()
ist die aktuelle Länge des binären Strings in out. Der binäre String in out
enthält das Starting Delimiter Symbol sowie die Länge.
Als Beispiel soll der binäre String "01234567890@ABCDE" bearbeitet werden.
Der Byte Stuffed String besteht aus: 0x10 0x01 für Starting Delimiter, 0x00
0x10 0x10 für die Byte-Stuffed Länge von 16 dezimal in Network Byte Order
und den Zeichen 0x30 0x31 0x32 0x33 0x34 0x35 0x36 0x37 0x38 0x39 0x40 0x41
0x42 0x43 0x44 0x45.
Programm: Base128 Transportkodierung
Werden
Binärdaten übertragen gibt es ein Delimiter Problem: Alle Bitkombinationen
werden für die Nutzdaten benutzt, es gibt keine freie Bitkombination für
Steuersymbole wie starting delimiter. Die Base128 Transportkodierung ist
eine Block-Kodierung. Um eine bessere Kodierung mit geringeren
Bandbreitenbedarf als bei Byte Stuffing zu erreichen, werden Nutzdaten zu
Blöcken zusammengefasst. Bei Base128 ist ein Block vor der
Transportkodierung 7 Bytes lang und nach der Kodierung 8 Bytes lang. Die
Base128 Kodierung trennt die 7 Eingangsdatenwerte jeweils in einen
niederwertigen Teil (Bit 0 bis 6) und einen höherwertigen Teil (Bit 7). Die
sieben niederwertigen Teile werden zuerst übertragen. Aus den 7
höherwertigen Teilen wird das achte Transportzeichen gebildet. Bei der
Kodierung wird aus dem Zahlenbereich 0..255 pro Datenwert der Zahlenbereich
0..127. Für die Übertragung wird zu dem Datenwert noch 33 dezimal als Offset
addiert. Dadurch liegt jeder Base128 Datenwert ausserhalb der ASCII
Steuerzeichen und ist auch kein ASCII Leerzeichen. Mit dem Offset ist
Base128 kompatibel zu Codepage 437, der vom IBM PC verwendeten 8 Bit
Erweiterung von ASCII.
7 6 5 4 3 2 1
0
7 6 5 4 3 2 1 0
+---------------+
+---------------+
| raw byte 0 | &
127 + 33 = |transport byte0|
+---------------+
+---------------+
| raw byte 1 | &
127 + 33 = |transport byte1|
+---------------+
+---------------+
| raw byte 2 | &
127 + 33 = |transport byte2|
+---------------+
+---------------+
| raw byte 3 | &
127 + 33 = |transport byte3|
+---------------+
+---------------+
| raw byte 4 | &
127 + 33 = |transport byte4|
+---------------+
+---------------+
| raw byte 5 | &
127 + 33 = |transport byte5|
+---------------+
+---------------+
| raw byte 6 | &
127 + 33 = |transport byte6|
+---------------+
+---------------+
Bit 7 aller raw bytes + 33 =
|transport byte7|
+---------------+
Bild: Base128 Transportkodierung
Programm Test
Programm kompilieren mit
gcc -Wall -o base128 base128.c
Nach der Eingabe:
./base128 1234567
erfolgt die Ausgabe:
Base128 von 1234567 ist: RSTUVWX!
len ist: 8
Binaer von RSTUVWX! ist: 1234567
len ist: 7
Datei
base128.c
#include
<stdio.h>
#include <string.h>
enum {EM = 0x19}; /* Steuersymbol End of Medium
*/
/* 7 Bytes Binaerdaten nach 8 Bytes Base128 Daten umwandeln */
void blockEncode(unsigned char *outBuf, const unsigned char *inBuf, int len)
{
int i, tb7 = 0, mask = 1;
memset(outBuf, EM, 7);
for (i = 0; i < len; ++i, ++inBuf) {
outBuf[i] = (*inBuf & 0x7F) +
33;
if ((*inBuf & 0x80) != 0)
{
tb7 |=
mask;
}
mask +=
mask; // 1, 2, 4, 8, ..
}
outBuf[7] = tb7 + 33;
}
/* 8 Bytes Base128 Daten nach 7 Bytes Binaerdaten umwandeln
* Returnwert: Laenge des outBuf
*/
int blockDecode(unsigned char *outBuf, const unsigned char *inBuf) {
int i, tb7 = inBuf[7] - 33, mask = 1;
for (i = 0; i < 7; ++i, ++inBuf, ++outBuf) {
if (EM == *inBuf) return i;
*outBuf = *inBuf - 33;
if ((tb7 & mask) != 0) {
*outBuf
|= 0x80;
}
mask += mask;
}
return 7;
}
/* inLen Bytes Binaerdaten nach maximal outSize Base128 Daten umwandeln
* Returnwert: Laenge des outBuf oder -1 bei Fehler
*/
int base128Encode(unsigned char *outBuf, int outSize, const unsigned char
*inBuf, int inLen) {
int outLen = 0;
while (inLen > 0 && outLen <= outSize - 8)
{
int len = inLen;
if (len > 7) len = 7;
blockEncode(outBuf, inBuf,
len);
inBuf += 7;
inLen -= len;
outBuf += 8;
outLen += 8;
}
if (0 == inLen) return outLen;
return -1;
}
/* inLen Bytes Base128 Daten nach maximal outSize Binaerdaten umwandeln
* Returnwert: Laenge des outBuf oder -1 bei Fehler
*/
int base128Decode(unsigned char *outBuf, int outSize, const unsigned char
*inBuf, int inLen) {
int outLen = 0;
while (inLen > 0 && outLen <= outSize - 7)
{
int len = blockDecode(outBuf,
inBuf);
inBuf += 8;
inLen -= 8;
outBuf += 7;
outLen += len;
}
if (0 == inLen) return outLen;
return -1;
}
int main(int argc, char *argv[]) {
if (argc < 2) {
printf("usage: base128
string\n");
return 1;
}
unsigned char *inBuf = argv[1];
int inLen = strlen(inBuf);
unsigned char outBuf[129];
int outSize = sizeof outBuf -1;
int len = base128Encode(outBuf, outSize, inBuf,
inLen);
if (len < 0) {
printf("Fehler bei Base128
Encode\n");
return 1;
}
outBuf[len] = '\0';
printf("Base128 von %s ist: %s\n", inBuf, outBuf);
printf("len ist: %d\n", len);
unsigned char outBuf2[129];
int outSize2 = sizeof outBuf2 -1;
int len2 = base128Decode(outBuf2, outSize2, outBuf,
len);
if (len2 < 0) {
printf("Fehler bei Base128
Decode\n");
return 1;
}
outBuf2[len2] = '\0';
printf("Binaer von %s ist: %s\n", outBuf, outBuf2);
printf("len ist: %d\n", len2);
return 0;
}
Programm: TCP Client und Server mit C-String
Schnittstelle
Der folgende Quelltext benutzt '\n' (ASCII Zeichen LF) als
Delimiter Zeichen. C-Strings können mit den system-calls fputs() oder
fprintf() gesendet werden und können mit fgets() empfangen werden.
Der system-call fflush() sorgt dafür das die Daten sofort im Netzwerk
übertragen werden. Normalerweise wartet die C-Bibliothek mit dem Aussenden
bis der Sende-Puffer voll ist. Dieses Verhalten ist bei interaktiven System
nicht gewünscht. Hier erwartet der Benutzer umgehende System-Reaktion.
Programm Test
Programme kompilieren mit
gcc -Wall -o stream_server stream_server.c
gcc -Wall -o stream_client stream_client.c
Im ersten xterm Fenster eingeben für TCP-Server:
./stream_server
Im zweiten xterm Fenster eingeben für TCP-Client
./stream_client hostname
Übung
1
Ändern Sie für die Dateien stream_client1.c und stream_server1.c die
Konstante SIZE auf 41 und testen Sie mit Eingaben die länger als 40 Zeichen
sind. Gibt es einen Unterschied zwischen der tcp_server/tcp_client Lösung
und der stream_server1/stream_client1 Lösung?
Geben Sie vor dem Aufruf von stream_client1 oder stream_server1 das Kommando
ein:
stty -F /dev/tty -icanon
Testen Sie erneut mit Eingaben die länger als 40 Zeichen sind. Welche
Auswirkung hat das Ausschalten der Zeilenpufferung des Terminals?
Übung
2
Testen Sie tcp_server zusammen mit stream_client1. Testen Sie
stream_server1 zusammen mit tcp_client. Funktionieren Eingaben kürzer als 40
Zeichen und Eingaben länger als 40 Zeichen wie erwartet?
Datei
stream_client.c
#include
<stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <netdb.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#define PORT 55555
#define SIZE 1400
// Funktion fuer TCP Partner Kommunikations Schleife
int do_chat(int fdKbd, int fdPartner) {
FILE *fpPartner = fdopen(fdPartner, "a+"); // mit buffered IO
arbeiten
if(NULL == fpPartner) {
perror("do_chat fdopen");
exit(1);
}
for(;;) {
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(fdPartner, &readfds);
FD_SET(fdKbd, &readfds);
int rv = select(32, &readfds, NULL, NULL, NULL);
if (-1 == rv) {
perror("do_chat select");
exit(1);
}
if (rv > 0) {
if (FD_ISSET(fdKbd, &readfds))
{ // Daten vom Keyboard verfuegbar
char buf[SIZE];
fgets(buf, sizeof buf,
stdin); // Zeile bis \n einlesen
fputs(buf,
fpPartner);
fflush(fpPartner);
// sofort auf das Netzwerk ausgeben
}
if (FD_ISSET(fdPartner, &readfds))
{ // Daten vom Netzwerk verfuegbar
char buf[SIZE];
char *rv = fgets(buf,
sizeof(buf), fpPartner);
if (NULL == rv) {
// Verbindung von
Gegenseite geschlossen oder Fehler
perror("do_chat
fgets");
fclose(fpPartner);
return -1;
}
printf("%s", buf);
fflush(stdout);
}
}
}
}
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "stream_client usage: stream_client
hostname\n");
exit(1);
}
struct hostent *he;
he = gethostbyname(argv[1]);
if (NULL == he) {
perror("stream_client gethostbyname");
exit(1);
}
int fdServer = socket(AF_INET, SOCK_STREAM, 0);
if (-1 == fdServer) {
perror("stream_client socket");
exit(1);
}
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof serv_addr);
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr = *((struct in_addr *) he->h_addr);
serv_addr.sin_port = htons(PORT);
int rv = connect(fdServer, (struct sockaddr *)&serv_addr, sizeof
serv_addr);
if (-1 == rv) {
perror("stream_client connect");
exit(1);
}
do_chat(STDIN_FILENO, fdServer);
return 0;
}
Datei
stream_server.c
// #include und
#define wie bei stream_client.c
// do_chat() wie bei
stream_client.c
int main() {
int fdListen = socket(AF_INET, SOCK_STREAM, 0);
if (-1 == fdListen) {
perror("stream_server socket");
exit(1);
}
int val = 1;
int rv = setsockopt(fdListen, SOL_SOCKET, SO_REUSEADDR, &val,
sizeof val);
if (-1 == rv) {
perror("stream_server setsockopt");
exit(1);
}
struct sockaddr_in my_addr;
memset(&my_addr, 0, sizeof my_addr);
my_addr.sin_family = AF_INET;
my_addr.sin_addr.s_addr = INADDR_ANY;
my_addr.sin_port = htons(PORT);
rv = bind(fdListen, (struct sockaddr *) &my_addr, sizeof
my_addr);
if (-1 == rv) {
perror("stream_server bind");
exit(1);
}
rv = listen(fdListen, 5);
if (-1 == rv) {
perror("stream_server listen");
exit(1);
}
for(;;) {
struct sockaddr_in addr;
socklen_t addrlen = sizeof addr;
int fdClient = accept(fdListen, (struct sockaddr
*)&addr, &addrlen);
if (-1 == fdClient) {
perror("stream_server accept");
continue;
}
printf("stream_server connected from %s\n",
inet_ntoa(addr.sin_addr));
do_chat(STDIN_FILENO, fdClient);
printf("stream_server closed from %s\n",
inet_ntoa(addr.sin_addr));
}
return 0;
}
Programm: TCP Client/Server mit TCP keep-alive
Wird
nach dem Verbindungsaufbau zwischen TCP Client und TCP Server die LAN
Verbindung unterbrochen bemerken dies weder der Client noch der Server. Mit
der Option SO_KEEPALIVE von setsockopt() wird das Aussenden von
Verbindung-Test-Meldungen (keep-alive messages) aktiviert. In der Default
Einstellung werden die ersten keep-alive Meldungen nach 2 Stunden
Inaktivität (idle, kein Transport von Nutzdaten) ausgesandt. Unter Linux
lassen sich die keep-alive Parameter nach Belieben einstellen. Die nötigen
Optionen sind TCP_KEEPIDLE für die Idle Zeit, TCP_KEEPINTVL für die Zeit
zwischen zwei keep-alive Meldungen und TCP_KEEPCNT für Anzahl der nicht
beantworteten keep-alive Meldungen die zum Verbindung-Abbau führen. Siehe
"man 7 tcp" für Details.
Damit TCP Client und TCP Server eine Leitungsunterbrechung feststellen
können, müssen beide Seiten die keep-alive Meldungen aktivieren.
Programm Test
Programme kompilieren mit
gcc -Wall -o keepalive_server keepalive_server.c
gcc -Wall -o keepalive_client keepalive_client.c
Im ersten xterm Fenster eingeben für TCP-Server:
./keepalive_server
Im zweiten xterm Fenster eingeben für TCP-Client
./keepalive_client hostname
Übung
Lassen die die beiden Programme auf
getrennten Computern laufen. Was passiert nach einer Leitungsunterbrechung?
Zum Vergleich testen Sie noch einmal mit stream_server und stream_client.
Bemerken diese Programme eine Leitungsunterbrechung? Was passiert wenn
während einer Leitungsunterbrechung eine Nutzdaten Meldung ausgesendet
wird?
Datei
keepalive_client.c
// #include und
#define wie bei stream_client.c und zusaetzlich
#include <netinet/tcp.h>
// fuer TCP_KEEP... (Linux spezifisch)
// do_chat() wie bei
stream_client.c
// Wrapper um setsockopt()
void mysetsockopt(int fd, int level, int option, int value) {
int rv = setsockopt(fd, level, option, &value, sizeof value);
if (-1 == rv) {
perror("keepalive_client setsockopt");
exit(1);
}
}
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "keepalive_client usage: keepalive_client
hostname\n");
exit(1);
}
struct hostent *he;
he = gethostbyname(argv[1]);
if (NULL == he) {
perror("keepalive_client gethostbyname");
exit(1);
}
int fdServer = socket(AF_INET, SOCK_STREAM, 0);
if (-1 == fdServer) {
perror("keepalive_client socket");
exit(1);
}
mysetsockopt(fdServer, SOL_SOCKET, SO_KEEPALIVE, 1);
mysetsockopt(fdServer, IPPROTO_TCP, TCP_KEEPIDLE, 4); //
Linux spezifisch
mysetsockopt(fdServer, IPPROTO_TCP, TCP_KEEPINTVL, 4); // Linux
spezifisch
mysetsockopt(fdServer, IPPROTO_TCP, TCP_KEEPCNT,
1); // Linux spezifisch
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof serv_addr);
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr = *((struct in_addr *) he->h_addr);
serv_addr.sin_port = htons(PORT);
int rv = connect(fdServer, (struct sockaddr *)&serv_addr, sizeof
serv_addr);
if (-1 == rv) {
perror("keepalive_client connect");
exit(1);
}
do_chat(STDIN_FILENO, fdServer);
return 0;
}
Datei
keepalive_server.c
// #include und
#define wie bei stream_client.c und zusaetzlich
#include <netinet/tcp.h>
// fuer TCP_KEEP... (Linux spezifisch)
// do_chat() wie bei
stream_client.c
// mysetsockopt() wie bei
keepalive_client.c
int main() {
int fdListen = socket(AF_INET, SOCK_STREAM, 0);
if (-1 == fdListen) {
perror("keepalive_server socket");
exit(1);
}
mysetsockopt(fdListen, SOL_SOCKET, SO_REUSEADDR, 1);
struct sockaddr_in my_addr;
memset(&my_addr, 0, sizeof my_addr);
my_addr.sin_family = AF_INET;
my_addr.sin_addr.s_addr = INADDR_ANY;
my_addr.sin_port = htons(PORT);
int rv = bind(fdListen, (struct sockaddr *) &my_addr, sizeof
my_addr);
if (-1 == rv) {
perror("keepalive_server bind");
exit(1);
}
rv = listen(fdListen, 5);
if (-1 == rv) {
perror("keepalive_server listen");
exit(1);
}
for(;;) {
struct sockaddr_in addr;
socklen_t addrlen = sizeof addr;
int fdClient = accept(fdListen, (struct sockaddr
*)&addr, &addrlen);
if (-1 == fdClient) {
perror("keepalive_server accept");
continue;
}
printf("keepalive_server conn. from %s\n",
inet_ntoa(addr.sin_addr));
mysetsockopt(fdClient, SOL_SOCKET, SO_KEEPALIVE, 1);
mysetsockopt(fdClient, IPPROTO_TCP, TCP_KEEPIDLE,
4); // Linux spezifisch
mysetsockopt(fdClient, IPPROTO_TCP, TCP_KEEPINTVL,
4); // Linux spezifisch
mysetsockopt(fdClient, IPPROTO_TCP, TCP_KEEPCNT,
1); // Linux spezifisch
do_chat(STDIN_FILENO, fdClient);
printf("keepalive_server closed from %s\n",
inet_ntoa(addr.sin_addr));
}
return 0;
}
Nicht-blockierende Ein-/Ausgabe (slow
system-call)
Wie im Programm tcp_client.c schon festgestellt ist
connect() ein langsamer system-call. Der connect() dauert 3 Sekunden wenn
der TCP-Server Computer im Netzwerk nicht läuft. Während dieser Zeit wird
die Event Schleife nicht ausgeführt. Das Programm reagiert nicht auf
Nutzer-Eingaben.
Mit der O_NONBLOCK Option des fcntl() system-calls kann das Verhalten des
connect() von blockierend auf nicht blockierend geändert werden. Der
connect() system-call mit NONBLOCK dauert nicht länger als ein normaler
system-call. Die TCP Verbindung-Aufbau über das Netzwerk benötigt aber
weiterhin seine Zeit von 3 Sekunden.
Wird connect() mit NONBLOCK verwendet muss die Applikation 3 Sekunden
abwartet und dann nachfragen ob der TCP Verbindungsaufbau erfolgreich war.
Dieses Nachfragen erfolgt mit der Option SO_ERROR des getsockopt()
system-calls.
Für die Änderung auf nicht-blockierendes connect() wird der Abschnitt in
keepalive_client.c:
int rv = connect(fdServer,
(struct sockaddr *)&serv_addr, sizeof serv_addr);
if (-1 == rv) {
perror("keepalive_client connect");
exit(1);
}
ersetzt durch folgenden Abschnitt:
int flags = fcntl(fdServer,
F_GETFL, 0);
if (-1 == flags) {
perror("nonblock_client fcntl F_GETFL");
exit(1);
}
int rv = fcntl(fdServer, F_SETFL, flags | O_NONBLOCK);
if (-1 == rv) {
perror("nonblock_client fcntl F_SETFL");
exit(1);
}
rv = connect(fdServer, (struct sockaddr *)&serv_addr, sizeof
serv_addr);
if (-1 == rv) {
extern int errno;
if (errno != EINPROGRESS)
{ // Error in
Progress wird erwartet
perror("nonblock_client connect");
exit(1);
}
}
printf("connect() NONBLOCK fertig\n");
sleep(3); // TCP Verbindungsaufbau durch
Betriebssystem abwarten
printf("sleep() fertig\n");
int err = 0;
unsigned len = sizeof err;
getsockopt(fdServer, SOL_SOCKET, SO_ERROR, &err, &len);
if (err != 0) {
fprintf(stderr, "nonblock_client getsockopt: %s\n",
strerror(err));
exit(1);
}
Übung
Datei keepalive_client.c nach
nonblock_client.c ändern. Den connect() Abschnitt auswechseln. Folgende
Header Dateien sind zusätzlich nötig:
#include
<fcntl.h>
#include <errno.h>
Programm Test
Programm kompilieren mit
gcc -Wall -o nonblock_client nonblock_client.c
Im ersten xterm Fenster eingeben für TCP-Server:
./keepalive_server
Im zweiten xterm Fenster eingeben für TCP-Client
./nonblock_client localhost
Programm: Zeitauflösung Linux Uhrzeit
Mit dem
system-call time() wird die Uhrzeit mit Zeitauflösung Sekunde angegeben. Bei
dem system-call gettimeofday() ist die Auflösung Mikro-Sekunde (1.000.000
Mikro-Sekunden sind 1 Sekunde).
Die gettimeofday() Uhrzeit steckt in zwei struct Variablen (tv_sec und
tv_usec). Mit Hilfe des Datentyp long long (64 Bit Integer) lässt sich die
gettimeofday() Uhrzeit in einer Variablen abbilden.
struct timeval
tv;
gettimeofday(&tv,
NULL);
long long t = 1000000 *
tv.tv_sec + tv.tv_usec;
printf("gettimeofday time is
%lld\n", t);
Programm Test
Programm kompilieren mit
gcc -Wall -o gettimeofday gettimeofday.c
Im xterm Fenster eingeben:
./gettimeofday
Übung
Testen Sie gettimeofday auf verschiedenen
Computern. Ist die Zeitauflösung immer gleich?
Datei
gettimeofday.c
#include
<stdio.h>
#include <sys/time.h>
int main() {
struct timeval tv[11];
gettimeofday(tv + 0, NULL);
int i;
for(i = 1; i < 11; ++i) {
for(;;) {
// eine
busy waiting Schleife
gettimeofday(tv + i, NULL);
if (tv[i].tv_sec != tv[i-1].tv_sec ||
tv[i].tv_usec != tv[i-1].tv_usec) {
break;
}
}
}
for(i = 1; i < 11; ++i) {
long long t0 = 1000000 * tv[i-1].tv_sec +
tv[i-1].tv_usec;
long long t1 = 1000000 * tv[i].tv_sec +
tv[i].tv_usec;
printf("gettimeofday Aufloesung = %lld usec\n", t1 -
t0);
}
return 0;
}
Fehlersuche mit valgrind memory
debugger
Ein typischer Fehler im Programm gettimeofday.c wäre die erste for() Schleife mit dem Anfangswert 0
zu schreiben:
for(i = 0; i < 11; ++i)
{
Dieser Fehler wird vom C-Compiler nicht gefunden, auch nicht wenn
die Option -fstack-protector-all benutzt wird. Das Programm läuft auch
scheinbar fehlerfrei. Erst der memory debugger in valgrind findet den
Fehler. Für gute valgrind Fehlerausgaben sollte man das Programm mit den
zusätzlichen Optionen -g und -O0 übersetzen.
gcc -g -O0 -Wall -o
gettimeofday gettimeofday.c
Dann das Programm unter valgrind memory leak check laufen
lassen.
valgrind --leak-check=yes
./gettimeofday
Die relevante Fehlermeldung ist
==5564== Conditional jump or
move depends on uninitialised value(s)
==5564== at 0x8048462: main (gettimeofday.c:25)
In Zeile 25 steht:
if (tv[i].tv_sec
!= tv[i-1].tv_sec || tv[i].tv_usec != tv[i-1].tv_usec)
{
Mit i = 0 ergibt der Ausdruck i-1 den Wert -1. Und einen
tv[-1].tv_sec gibt es nicht. Für weitere Dokumentation über valgrind siehe
http://www.valgrind.org/docs/manual/index.html
Signale
Mit Signalen meldet sich das Betriebssystem
Linux bei der Applikation. Die Taste Strg-C löst das Signal SIGINT aus. Ein
"killall -9 Programmname" löst das Signal SIGKILL aus. Siehe "man 7 signal"
für die Liste der Signale.
Ohne eigene Programmierung führt ein Signal zum Programm-Ende. Mit dem
signal() system-call wird die Reaktion auf Signale geändert. Die Signale
SIGINT (Strg-C von der Tastatur), SIGTERM (Strg-D von der Tastatur), SIGTSTP
(Strg-Z von der Tastatur) können ignoriert werden. Dazu schreibt man am
Anfang der main() Funktion:
signal(SIGINT,
SIG_IGN); // Strg-C ignorieren
signal(SIGTERM,
SIG_IGN); // Strg-D ignorieren
signal(SIGTSTP,
SIG_IGN); // Strg-Z ignorieren
Die Include Datei für signal() ist
#include <signal.h>
Übung
Erweitern Sie tcp_server.c zu tcp_servera.c
um die obige Signal Behandlung. Testen Sie das Programm mit Strg-C, Strg-D,
Strg-Z. Das Programm kann nur noch mit "killall -9 tcp_servera" beendet
werden. Das Signal SIGKILL (Signal Nummer 9) kann nicht ignoriert
werden.
EINTR
Behandlung bei select()
Das mögliche Auftreten von Signalen ist der
Grund für die spezielle Behandlung des return value (rv) von select(). Der
Fehler EINTR bedeutet "ein nicht-blockiertes Signal ist aufgetreten". Dieser
Fehler ist kein echter Fehler der zum Programm-Ende führen soll. Zwischen
den beiden UNIX Versionen von AT&T und BSD gibt es deutliche
Unterschiede im Verhalten bei Signalen. Ein Betriebssystem Aufruf wie
select(), read(), write() oder open() wird bei AT&T UNIX bei einem
Signal beendet. Bei einem BSD UNIX wird nach dem Aufruf des Signal Handler
der Betriebssystem-Aufruf weiter ausgeführt. Die GNU Libc und damit auch
Linux verhalten sich defaultmäßig wie ein AT&T UNIX.
int rv = select(32,
&readfds, NULL, NULL, NULL);
if (-1 == rv)
{
extern
int errno;
if
(errno != EINTR) {
//
Signal erhalten, entsprechender Quelltext ...
perror("select");
exit(1);
}
}
if (rv > 0)
{
if
(FD_ISSET(STDIN_FILENO, &readfds)) {
//
Daten vom Keyboard verfuegbar, entsprechender Quelltext ...
}
}
Achtung: Das Bit-Feld readfds darf nur verwendet werden wenn rv > 0 ist.
Bei -1 == rv ist das Bit-Feld readfds undefiniert. Siehe select man
page.
Programm: Intervall Timer
Ein Intervall Timer
(periodischer Aufruf einer Funktion) kann unter Linux auf verschiedene Arten
realisiert werden:
- mit dem time-out Parameter von select()
- setitimer()
Die beste Möglichkeit ist setitimer(). Der Timer muss nur einmal
eingerichtet werden und meldet sich dann immer wieder.
Leider ist die Benutzung von setitimer() nicht ganz einfach. Einige
Bedingungen müssen im Programm erfüllt sein:
- es muss einen SIGALRM Handler geben (dieses Signal wird
ausgelöst)
- die Timer-Funktion ergibt sich aus select() mit return value = -1 und
errno = EINTR
Programm Test
Programm kompilieren mit
gcc -Wall -o setitimer setitimer.c
Im xterm Fenster eingeben:
stty -F /dev/tty -icanon
./setitimer
Das Programm gibt 1000 Punkte aus. Der Timer ist auf knapp 4msec gestellt,
d.h. das Programm benötigt 4000msec = 4sec für die Ausgabe.
Übung
1
Testen Sie das Programm mit "time ./setitimer". Ändern Sie nun die
Timer-Konstante von 4000-2 (d.h. 3998) auf 4000. Testen Sie das
Programm erneut. Was passiert? Testen Sie weiter. Benutzen Sie folgende
Timer-Konstanten:
10000-2 (d.h. 9998)
10000
1000-2 (d.h. 998)
1000
Was ist die Intervall Timer Zeitauflösung?
Übung
2
Halten Sie die Taste A gedrückt während das Programm setitimer läuft.
Was passiert mit der Ausgabe "dots" und "chars". Was passiert mit der time
Ausgabe?
Übung
3
Die Ausgabe write(STDOUT_FILENO, s, strlen(s)) kann auch in der
alarmhandler() Funktion stehen. Schieben Sie die nötigen zwei Programmzeilen
aus der main() Funktion in die alarmhandler() Funktion und testen Sie die
neue Programmversion setitimer1.c.
Datei
setitimer.c
#include
<stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <unistd.h>
#include <signal.h>
#include <sys/time.h>
#include <sys/select.h>
void alarmhandler() {
// absichtlich nichts tun
}
int main() {
signal(SIGALRM, alarmhandler);
struct itimerval value;
value.it_interval.tv_sec = value.it_value.tv_sec = 0;
value.it_interval.tv_usec = value.it_value.tv_usec =
4000-2;
setitimer(ITIMER_REAL, &value, NULL);
int chars = 0;
int dots;
for(dots = 0; dots < 1000;) { //
absichtlich kein ++dots hier
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(STDIN_FILENO, &readfds);
int rv = select(32, &readfds, NULL, NULL, NULL);
if (-1 == rv) {
extern int errno;
if (errno != EINTR) {
perror("setitimer select");
exit(1);
}
// Signal erhalten, d.h. ein setitimer()
Intervall ist abgelaufen
++dots;
// hier kommt Schleifenzaehler hochzaehlen
char s[] = ".";
write(STDOUT_FILENO, s,
strlen(s)); // ungepuffert ausgeben
}
if (rv > 0) {
if (FD_ISSET(STDIN_FILENO, &readfds))
{ // Daten vom Keyboard verfuegbar
char buf[1];
read(STDIN_FILENO, buf, sizeof
buf); // Puffer leer lesen
++chars;
}
}
}
printf("\ndots = %d chars = %d\n", dots, chars);
return 0;
}
Programm: TCP client mit setitimer()
Die Programme
werden langsam größer. Der Quelltext muss gegliedert werden um nicht die
Übersicht und die Wartbarkeit zu verlieren. Für die Strukturierung ist die
Unterteilung des Quelltextes in Software-Schichten (software layers) sehr
hilfreich. Eine höhere Software-Schicht ist immer etwas abstrakter als die
darunter liegende Softwareschicht.
Eine höhere Softwareschicht bietet oft auch mehr Funktionalität. In unserem
Fall werden anstelle von nur einem setitimer() Intervall-Timer insgesamt 32
after() Timer angeboten.
Mit den Funktionen after() und fileevent_readable() wird das Konzept von
events (Ereignissen) und event-handler Funktionen vertieft. Im Kapitel
Signale und im Programm setitimer.c wurden events (z.B. das Signal SIGINT)
und event-handler (z.B. die Funktion alarmhandler()) schon eingeführt.
Event-handler Funktionen werden auch call-back Funktionen genannt.
Die Namen vwait, after, after cancel, fileevent readable und socket -async
stammen übrigens von der Programmiersprache Tcl/Tk und sind dort Tcl/Tk
Funktionen.
| Höhere Schicht |
Aufgabe |
Niedrigere Schicht |
| vwait_init() |
Daten für Event Schleife initialisieren |
nicht vorhanden |
| after() |
Zeit gesteuerter Funktionsaufruf |
basiert auf setitimer() |
| after_cancel() |
Abbruch eines after() |
nicht vorhanden |
| fileevent_readable() |
Daten sind verfügbar |
basiert auf select() |
| vwait() |
Event Schleife ausführen |
nicht vorhanden |
socket_async()
|
TCP Client Socket nicht-blockierend
öffnen |
gethostbyname(), socket(),
connect()
|
Die Header Datei vwait.h erfüllt nebenbei die Aufgabe der Dokumentation für
die neuen Funktionen. Die Kommentare können von dem Dokumentation-Programm
doxygen ausgewertet werden. In der Quelltext-Datei vwait_client.c werden die
Funktionen der niedrigen Schicht nicht verwendet. Die Quelltext-Datei
vwait.c realisiert das “vwait Modul” durch eine prozedurale Abstraktion.
Programm Test
Programm kompilieren mit
gcc -Wall -o vwait_client vwait_client.c vwait.c
Im ersten xterm Fenster eingeben für TCP-Server:
./keepalive_server
Im zweiten xterm Fenster eingeben für TCP-Client
./vwait_client hostname
Übung
1
Ändern Sie SIZE auf den Wert 41 und testen Sie das Programm. Was
passiert wenn mehr als 40 Zeichen eingeben werden? Schalten Sie die
Zeilen-Pufferung des Terminals aus mit
stty -F /dev/tty -icanon
Wie verändert sich das Verhalten bei zu langen Eingaben?
Datei
vwait_client.c
#include
<stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <netdb.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/tcp.h> // fuer TCP_KEEP... (Linux
spezifisch)
#include "vwait.h"
#define PORT 55555
#define SIZE 1400
// Callback Funktion: Daten vom Keyboard verfuegbar
void cb_kbd(int fdKbd, void *pServer) {
FILE *fpServer = pServer;
char buf[SIZE];
fgets(buf, sizeof buf, stdin);
fputs(buf,
fpServer);
fflush(fpServer);
}
// Callback Funktion: Daten vom Netzwerk verfuegbar
void cb_Server(int fdServer, void *pServer) {
FILE *fpServer = pServer;
char buf[SIZE];
char *rv = fgets(buf, sizeof buf, fpServer);
if (NULL == rv) {
// Verbindung von Gegenseite geschlossen oder Fehler
perror("cb_Server fgets");
fclose(fpServer);
fileevent_readable(fdServer, NULL, NULL);
exit(1);
}
printf("%s", buf);
fflush(stdout);
}
// Callback Funktion: Timer ist abgelaufen
void cb_timeout(void *p) {
char s[] = ".";
write(1, s,
strlen(s)); //
ungepuffert auf Bildschirm ausgeben
after(1000, cb_timeout, NULL); // neuen Timer
starten
}
void mysetsockopt(int fd, int level, int option, int value) {
int rv = setsockopt(fd, level, option, &value, sizeof value);
if (-1 == rv) {
perror("vwait_client setsockopt");
exit(1);
}
}
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "vwait_client usage: vwait_client
hostname\n");
exit(1);
}
struct hostent *he;
he = gethostbyname(argv[1]);
if (NULL == he) {
perror("vwait_client gethostbyname");
exit(1);
}
int fdServer = socket(AF_INET, SOCK_STREAM, 0);
if (-1 == fdServer) {
perror("vwait_client socket");
exit(1);
}
mysetsockopt(fdServer, SOL_SOCKET, SO_KEEPALIVE, 1);
mysetsockopt(fdServer, IPPROTO_TCP, TCP_KEEPIDLE, 4); //
Linux spezifisch
mysetsockopt(fdServer, IPPROTO_TCP, TCP_KEEPINTVL, 4); // Linux
spezifisch
mysetsockopt(fdServer, IPPROTO_TCP, TCP_KEEPCNT,
1); // Linux spezifisch
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof serv_addr);
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr = *((struct in_addr *) he->h_addr);
serv_addr.sin_port = htons(PORT);
int rv = connect(fdServer, (struct sockaddr *)&serv_addr, sizeof
serv_addr);
if (-1 == rv) {
perror("vwait_client connect");
exit(1);
}
FILE *fpServer = fdopen(fdServer, "a+");
if(NULL == fpServer) {
perror("vwait_client fdopen");
exit(1);
}
vwait_init();
fileevent_readable(fdServer, cb_Server, fpServer);
fileevent_readable(STDIN_FILENO, cb_kbd, fpServer);
after(1000, cb_timeout, NULL);
vwait();
// Event Schleife ausfuehren
return 0;
}
Datei
vwait.h
#ifdef
__cplusplus // bei C++ Compiler definiert
extern "C" { // C
Namensumsetzung (name mangling) benutzen
#endif
/**
* vwait() Datenstrukturen initialisieren. Einmal bei Programmstart
aufrufen
*/
void vwait_init();
/**
* Zeitgesteuerter Funktions-Aufruf
* @param ms die Wartezeit in Millisekunden
* @param proc Zeiger auf eine Funktion mit einem void* Parameter
* @param param Zeiger auf void * Funktionsparameter
*
* return After Id, -1 bei Fehler
*/
int after(int ms, void (*proc)(void *), void *param);
/**
* Loesche Zeitgesteuerten Funktions-Aufruf
* @param afterId die AfterId von after()
*
* return 0 wenn okay, -1 bei Fehler
*/
int after_cancel(int afterId);
/**
* Filedescriptor Daten vorhanden Eventhandler
* @param fd der Filedescriptor (returnwert von open())
* @param proc Zeiger auf eine Funktion mit zwei Parameter (int, void
*)
* @param param Zeiger auf void * Funktionsparameter
*
* return 0 wenn okay, -1 bei Fehler
*/
int fileevent_readable(int fd, void (*proc)(int, void *), void *param);
/**
* vwait Eventloop. Hier verschwindet die Programmkontrolle
*/
void vwait();
/** TCP Client Socket nicht-blockierend oeffnen
* @param host Hostname
* @param port Portnummer
* return -1 bei Fehler, Filedescriptor sonst
*/
int socket_async(const char *host, int port);
#ifdef __cplusplus
}
#endif
Datei
vwait.c
#include
<stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <netdb.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/tcp.h> // fuer TCP_KEEP... (Linux
spezifisch)
#include <errno.h>
#include <fcntl.h>
#include <signal.h>
#include <sys/time.h>
#include "vwait.h"
#define INTERVAL 100 // in ms
#define MAXFD 32 //
maximale Anzahl fd fuer fileevent_readable()
#define MAXAFTER 32 // maximale Anzahl
wartende after() Aufrufe
/*************************************** */
/* after */
typedef struct {
void (*proc)(void *); // aufzurufende Funktion
void
*param; //
Parameter fuer aufzurufende Funktion
int
ms;
// Count Down in Millisekunden
int
magic;
// after(), after_cancel() Konsistenz Pruefwert
} AFTERENTRY;
static AFTERENTRY afterarray[MAXAFTER];
int after(int ms, void (*proc)(void *), void *param) {
int i;
for (i = 0; i < MAXAFTER; ++i) {
if (NULL == afterarray[i].proc)
{
// Eintrag ist frei
afterarray[i].proc = proc;
afterarray[i].ms = ms;
afterarray[i].param = param;
++afterarray[i].magic;
if (afterarray[i].magic >=
INT_MAX/MAXAFTER) { // vermeide Ueberlauf
afterarray[i].magic =
1;
}
return MAXAFTER * afterarray[i].magic +
i;
}
}
return
-1;
// kein freier after() Timer vorhanden
}
int after_cancel(int afterId) {
int id = afterId % MAXAFTER;
if (id < 0 || id >= MAXAFTER) {
return -1;
}
int magic = afterId / MAXAFTER;
if (magic != afterarray[id].magic) { // after_cancel() passt
nicht zu after()
return -1;
}
afterarray[id].proc = NULL;
afterarray[id].param = NULL;
afterarray[id].ms = 0;
return 0;
}
/*************************************** */
/* fileevent */
typedef struct {
void (*proc)(int, void *); // aufzurufende Funktion
void
*param;
// Parameter fuer aufzurufende Funktion
} FILEEVENTENTRY;
static fd_set readfds;
static FILEEVENTENTRY fileeventarray[MAXFD];
int fileevent_readable(int fd, void (*proc)(int, void *), void *param) {
if (fd < 0 || fd >= MAXFD) {
return -1;
}
if (proc != NULL) {
FD_SET(fd, &readfds);
} else {
FD_CLR(fd, &readfds);
}
fileeventarray[fd].proc = proc;
fileeventarray[fd].param = param;
return 0;
}
void vwait_init() {
FD_ZERO(&readfds);
memset(fileeventarray, 0, sizeof fileeventarray);
memset(afterarray, 0, sizeof afterarray);
}
/*************************************** */
/* vwait */
static void alarmhandler(int sig) {
// absichtlich nichts tun
}
void vwait() {
signal(SIGALRM, alarmhandler);
struct itimerval value;
value.it_interval.tv_sec = value.it_value.tv_sec = 0;
value.it_interval.tv_usec = value.it_value.tv_usec = INTERVAL *
1000;
setitimer(ITIMER_REAL, &value, NULL);
for(;;) {
fd_set in_out =
readfds; // select()
aendert den Parameter
int rv = select(MAXFD, &in_out, NULL, NULL,
NULL);
if (-1 == rv)
{
// setitimer() abgelaufen oder Fehler
extern int errno;
if (errno != EINTR) {
perror("vwait select");
exit(1);
}
int i;
for (i = 0; i < MAXAFTER; ++i) {
if (afterarray[i].proc != NULL)
{
afterarray[i].ms -=
INTERVAL;
if (afterarray[i].ms
<= INTERVAL/2) {
(*afterarray[i].proc)(afterarray[i].param);
afterarray[i].proc = NULL;
}
}
}
}
if (rv > 0)
{
// Daten fuer file descriptors vorhanden
int i;
for (i = 0; i < MAXFD; ++i) {
if (FD_ISSET(i, &in_out)
&& (fileeventarray[i].proc != NULL)) {
(*fileeventarray[i].proc)(i, fileeventarray[i].param);
}
}
}
}
}
int socket_async(const char *host, int port) {
struct hostent *he;
he = gethostbyname(host);
if (NULL == he) return -1;
int fdServer = socket(AF_INET, SOCK_STREAM, 0);
if (-1 == fdServer) return -1;
int val = 1;
int rv = setsockopt(fdServer, SOL_SOCKET, SO_KEEPALIVE, &val,
sizeof val);
if (-1 == rv) goto error1;
val = 4;
rv = setsockopt(fdServer, IPPROTO_TCP, TCP_KEEPIDLE, &val, sizeof
val);
if (-1 == rv) goto error1;
val = 4;
rv = setsockopt(fdServer, IPPROTO_TCP, TCP_KEEPINTVL, &val,
sizeof val);
if (-1 == rv) goto error1;
val = 1;
rv = setsockopt(fdServer, IPPROTO_TCP, TCP_KEEPCNT, &val, sizeof
val);
if (-1 == rv) goto error1;
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof serv_addr);
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr = *((struct in_addr *) he->h_addr);
serv_addr.sin_port = htons(port);
int flags = fcntl(fdServer, F_GETFL, 0);
if (-1 == flags) goto error1;
rv = fcntl(fdServer, F_SETFL, flags | O_NONBLOCK);
if (-1 == rv) goto error1;
rv = connect(fdServer, (struct sockaddr *)&serv_addr, sizeof
serv_addr);
if (-1 == rv) {
extern int errno;
if (errno != EINPROGRESS) goto error1;
// EINPROGRESS wird erwartet
}
return fdServer;
error1:
close(fdServer);
return -1;
}
State
Diagram (Zustands Übergang Diagramm)
Beim System-Design werden die
einzelnen Zustände als Kreise, Ellipsen oder Rechtecke dargestellt, die
Zustandsübergänge als gerichtete Pfeile zwischen den Kreisen. Die
Initialisierung der State-Machine (der Anfangszustand) wird oft mit einem
Pfeil "aus dem Nichts" mit der Beschriftung "Start" gekennzeichnet. Das TCP
Protokoll benutzt ein State-Diagram. Das FDDI Protokoll übrigens auch.
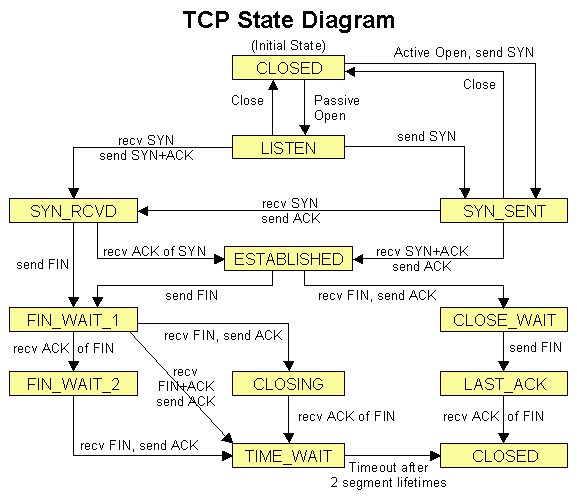
TCP State Diagram (http://world.std.com/~franl/tcp-state-diagram.gif)
Die Zustände "Listen", "Established (Verbunden)" usw. lassen sich mit dem
Programm netstat -antp ansehen. Hier die Ausgabe nachdem tcp_server und
tcp_client auf dem Computer gestartet wurden:
Proto Recv-Q Send-Q Local
Address Foreign
Address
State PID/Program name
tcp
0 0
0.0.0.0:55555
0.0.0.0:*
LISTEN 7303/tcp_server
tcp
0 0
127.0.0.1:32927
127.0.0.1:55555
VERBUNDEN 7304/tcp_client
tcp
0 0
127.0.0.1:55555
127.0.0.1:32927
VERBUNDEN 7303/tcp_server
Die erste Zeile mit State LISTEN zeigt das der tcp_server auf einen
Verbindungsaufbau wartet - auch wenn das Programm nur einen tcp_client
gleichzeitig bedienen kann. Die zweite Zeile ist die Verbindung aus Sicht
des tcp_client. Die dritte Zeile ist die Verbindung aus Sicht des
tcp_server.
Programm: TCP Client mit NONBLOCK, reopen
Im
Programm nonblock_client.c wurde nicht-blockierendes connect() vorgestellt.
Erst mit after() zum zeit-gesteuerten Funktionsaufruf machen
nicht-blockierende system-calls richtig Sinn.
Die Applikation führt den nicht-blockierenden system-call aus, wartet mit
after() auf das Ergebnis und benutzt dann die erfolgreich geöffnete
TCP-Verbindung.
Wie bei dem vwait Modul wird wieder das "Räderwerk" hinter einfachen
Zugriffsfunktionen versteckt (abstrahiert). Das Modul-Interface wird in
tcp.h definiert und umfasst:
| tcp_open() |
Öffne TCP Verbindung auf TCP-Client Seite |
| tcp_puts() |
Schreibe C-String buf in Richtung TCP Server |
| tcp_flush() |
Sofort aussenden (flush buffer) |
| tcp_gets() |
Lese C-String bis Zeilenende in buf mit Größe size vom
TCP-Server |
| tcp_close() |
Schließe TCP Verbindung auf TCP-Client Seite |
Die Funktionen sind nach den Stream-IO Funktionen fopen(), fputs(),
fflush(), fgets() und fclose() gestaltet. Die Funktion tcp_gets() blockiert
und sollte deshalb nur innerhalb eines mit fileevent_readable()
eingerichteten Event-Handlers benutzt werden.
Programm Test
Programm kompilieren mit
gcc -Wall -o single_client single_client.c vwait.c tcp.c
Im ersten xterm Fenster eingeben für TCP-Server:
./keepalive_server
Im zweiten xterm Fenster eingeben für TCP-Client
./single_client hostname portnummer
State
Diagram single_client
Das Programm single_client erfüllt natürlich das
TCP state diagram. Darüber hinaus hat das Programm noch sein eigenes State
Diagram.
Nach dem Start geht die durch das Modul tcp.c realisierte state machine in
den Zustand connect1. In diesem Zustand wird der erste Teil des TCP
connect() ausgeführt.
Nach 3 Sekunden time out erfolgt ein Übergang ist den Zustand connect2. In
diesem Zustand wird geprüft ob der TCP connect() erfolgreich war. Wenn
erfolgreich erfolgt ein Übergang zum Zustand transfer statt, sonst erfolgt
ein Übergang zum Zustand connect1.
In dem Zustand transfer können Daten mit tcp_puts() versendet werden und
Daten mit tcp_gets() empfangen werden. Treten Fehler im Zustand transfer
erfolgt ein Übergang zum Zustand reopen.
Im Zustand reopen wird die Verbindung geschlossen. Nach 1 Sekunde time-out
erfolgt ein Übergang zu Zustand connect1, die state machine ist wieder im
Anfangszustand.
Die state machine als Diagramm:
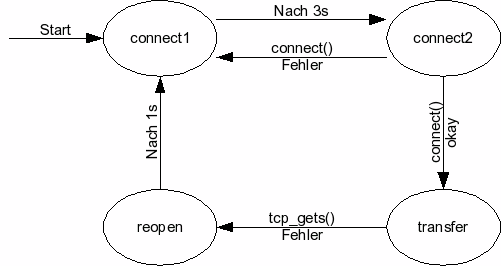
Übung
1
Die Zustände werden mit Hilfe der tcp_xxx() Funktionen realisiert.
Machen Sie die Zustände deutlich durch printf() Ausgaben am Anfang der
Funktionen. Benutzen Sie folgende Texte:
| Am Anfang von |
Ausgabe von |
| tcp_connect1() |
Zustand connect1 |
| tcp_connect2() |
Zustand connect2 |
| tcp_puts() |
Zustand transfer (puts) |
| tcp_gets() |
Zustand transfer (gets) |
| tcp_reopen() |
Zustand reopen |
Übung
2
Entfernen Sie die Funktion tcp_reopen() aus tcp.c. Das Programm
Verhalten soll gleich bleiben.
Datei
single_client.c
#include
<stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include "vwait.h"
#include "tcp.h"
#define SIZE 1400
// Callback Funktion: Daten vom Keyboard verfuegbar
void cb_Kbd(int fdKbd, void *dummy) {
char buf[SIZE];
fgets(buf, sizeof buf, stdin);
int rv = tcp_puts(buf);
if (-1 == rv) {
fprintf(stderr, "cb_Kbd tcp_puts failed\n");
return;
}
tcp_flush();
}
// Callback Funktion: Daten vom Netzwerk verfuegbar
void cb_Server(int fdServer, void *dummy) {
char buf[SIZE];
char *rv = tcp_gets(buf, sizeof buf);
if (NULL == rv) {
fprintf(stderr, "cb_Server tcp_gets failed\n");
return;
}
printf("%s", buf);
fflush(stdout);
}
int main(int argc, char *argv[]) {
if (argc != 3) {
fprintf(stderr, "single_client usage: single_client host
port\n");
exit(1);
}
const char *host = argv[1];
int port = atoi(argv[2]);
vwait_init();
tcp_open(host, port, cb_Server);
fileevent_readable(STDIN_FILENO, cb_Kbd, NULL);
vwait();
// Event Schleife ausfuehren
return 0;
}
Datei
tcp.h
/**
* Oeffne TCP Verbindung auf TCP-Client Seite mit Retry
* @param host_ Hostname passend fuer gethostbyname()
* @param port_ Portnummer
* @param callback Callback-Funktion passend fuer
fileevent_readable()
*/
void tcp_open(const char *host_, int port_, void (*callback)(int, void
*));
/**
* Schreibe C-String buf in Richtung TCP Server
* @param buf Zeiger auf 0-terminierten C-String
*
* return -1 bei Fehler, 0 sonst (wie bei fputs)
*/
int tcp_puts(const char *buf);
/**
* Sofort aussenden (flush buffer)
*
* return -1 bei Fehler, 0 sonst (wie bei fflush)
*/
int tcp_flush();
/**
* Lese C-String bis Zeilenende in buf mit Groesse size vom
TCP-Server
* @param buf Zeiger auf Puffer
* @param size Groesse des Puffers
*
* return NULL bei Fehler, buf sonst (wie bei fgets)
*/
char *tcp_gets(char *buf, int size);
/**
* Schliesse TCP Verbindung auf TCP-Client Seite
*
* return -1 bei Fehler, 0 sonst (wie bei fclose)
*/
int tcp_close();
Datei
tcp.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <netdb.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netinet/tcp.h> // fuer TCP_KEEP... (Linux
spezifisch)
#include <errno.h>
#include <fcntl.h>
#include "vwait.h"
#include "tcp.h"
static const char *host;
static int port;
static int fdServer;
static FILE *fpServer = NULL;
static void (*callback)(int, void *); // tcp_gets() Callback Funktion
static void tcp_connect1(void *dummy);
static void tcp_connect2(void *dummy);
void tcp_open(const char *host_, int port_, void (*callback_)(int, void *))
{
host = host_;
port = port_;
callback = callback_;
tcp_connect1(NULL);
}
// TCP Client connect Teil 1: connect() NONBLOCK
static void tcp_connect1(void *dummy) {
fdServer = socket_async(host, port);
if (fdServer < 0) {
perror("tcp_connect1 socket_async");
after(1000, tcp_connect1, NULL);
return;
}
after(3000, tcp_connect2, NULL);
}
// TCP Client connect Teil 2: Pruefen ob Verbindungsaufbau erfolgreich
war
static void tcp_connect2(void *dummy) {
int err = 0;
unsigned len = sizeof err;
getsockopt(fdServer, SOL_SOCKET, SO_ERROR, &err, &len);
if (err != 0) {
fprintf(stderr, "tcp_connect2 getsockopt: %s\n",
strerror(err));
goto error1;
}
fpServer = fdopen(fdServer, "a+");
if(NULL == fpServer) {
perror("tcp_connect2 fdopen");
goto error1;
}
fileevent_readable(fdServer, callback, fpServer);
fprintf(stderr, "tcp_connect2 success host = %s port = %d\n", host,
port);
return;
error1:
close(fdServer);
after(1000, tcp_connect1, NULL);
return;
}
int tcp_puts(const char *buf) {
if (NULL == fpServer) return -1;
return fputs(buf, fpServer);
}
int tcp_flush() {
if (NULL == fpServer) return -1;
return fflush(fpServer);
}
// TCP Client nach Fehler aufraeumen
static void tcp_reopen() {
tcp_close();
after(1000, tcp_connect1, NULL);
}
char *tcp_gets(char *buf, int size) {
char *rv = fgets(buf, size, fpServer);
if (NULL == rv) { // Verbindung
von Gegenseite geschlossen oder Fehler
tcp_reopen();
buf[0] = '\0';
}
return rv;
}
int tcp_close() {
int rv = fclose(fpServer);
fpServer = NULL;
fileevent_readable(fdServer, NULL, NULL);
fdServer = -1;
return rv;
}
Go To
Statement Considered Harmful
Im Jahr 1968 schrieb Edsger W. Dijkstra
sein berühmtes "A case
against the GO TO Statement". In der Funktionen socket_async() und
tcp_connect2() wird goto verwendet. Auch das unstrukturierte goto kann der
strukturierten Programmierung dienen. Das goto error1 ist ein Sprung zum
Fehler-Aufräum Quelltext (error recovery code) der Funktion. Dieses goto ist
mehr strukturiert als die Wiederholung des Fehler-Aufräum Quelltextes an
mehreren Stellen in der Funktion.
Programm: TCP Client für redundante TCP-Server
Das
letzte Programm der TCP Client Serie fügt noch eine kleine Erweiterung
hinzu. Der TCP Client versucht wechselweise zu zwei unterschiedlichen TCP
Servern Verbindung aufzubauen. Diese Methode wird bei einigen redundanten
Systemen eingesetzt.
Die Änderungen im Quelltext sind minimal. Die Funktion tcp_open2() erhält
die IP Information für zwei TCP Server. Die Funktion tcp_connect1() tauscht
die TCP Server IP Informationen aus damit einmal der eine Server und im
nächsten Durchlauf der andere Server zum Verbindungsaufbau benutzt wird.
Programm Test
Programm kompilieren mit
gcc -Wall -o dual_client dual_client.c vwait.c tcp2.c
Im ersten xterm Fenster eingeben für TCP-Server:
./keepalive_server1 55555
Im zweiten xterm Fenster eingeben für TCP-Server:
./keepalive_server1 55556
Im dritten xterm Fenster eingeben für TCP-Client
./dual_client localhost 55555 localhost 55556
Beispiel Sitzung
Die Benutzer Eingaben waren:
abcd
Nun Server auf Port 55555 beenden
efgh
Nun auch Server auf Port 55556 beenden
./dual_client localhost 55555
localhost 55556
tcp_connect2 success host = localhost
port = 55555
abcd
Nun Server auf Port 55555
beenden
cb_Server tcp_gets
failed
tcp_connect2 success host = localhost
port = 55556
efgh
Nun auch Server auf Port 55556
beenden
cb_Server tcp_gets
failed
tcp_connect2 getsockopt: Connection
refused
tcp_connect2 getsockopt: Connection
refused
tcp_connect2 getsockopt: Connection
refused
tcp_connect2 getsockopt: Connection
refused
Datei
dual_client.c
#include
<stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include "vwait.h"
#include "tcp2.h"
#define SIZE 1400
// Callback Funktion: Daten vom
Keyboard verfuegbar
// cb_Kbd() wie bei
single_client.c
// Callback Funktion: Daten vom
Netzwerk verfuegbar
// cb_Server() wie bei
single_client.c
int main(int argc, char *argv[]) {
if (argc != 5) {
fprintf(stderr, "dual_client usage: dual_client host port
host2 port2\n");
exit(1);
}
const char *host = argv[1];
int port = atoi(argv[2]);
const char *host2 = argv[3];
int port2 = atoi(argv[4]);
vwait_init();
tcp_open2(host, port, host2, port2, cb_Server);
fileevent_readable(STDIN_FILENO, cb_Kbd, NULL);
vwait();
// Event Schleife ausfuehren
return 0;
}
Datei
tcp2.h
/**
* Oeffne TCP Verbindung auf TCP-Client Seite fuer redundante
TCP-Server
* @param host_ Hostname passend fuer gethostbyname()
* @param port_ Portnummer
* @param host2_ Hostname alternativer TCP-Server
* @param port2_ Portnummer alternativer TCP-Server
* @param callback Callback-Funktion passend fuer
fileevent_readable()
*/
void tcp_open2(const char *host_, int port_, const char *host2_, int
port2_,
void (*callback_)(int, void *));
// Rest wie bei tcp.h
Datei
tcp2.c
// zusaetzliche Variablen
gegenueber tcp.c
static const char *host2 =
""; // Hostname alternativer TCP
Server
static int port2 =
-1;
// Portnummer alternativer TCP Server
// geaenderte Funktion gegenueber
tcp.c
void tcp_open(const char *host_, int
port_, void (*callback_)(int, void *)) {
host = host2 = host_;
port = port2 = port_;
callback = callback_;
tcp_connect1(NULL);
}
// neue Funktion
gegenueber tcp.c
static void tcp_swapServer() {
const char *hostTmp = host; // Dreier-Tausch
host = host2;
host2 = hostTmp;
int portTmp =
port; //
Dreier-Tausch
port = port2;
port2 = portTmp;
}
// neue Funktion gegenueber
tcp.c
void tcp_open2(const char *host_, int
port_, const char *host2_, int port2_,
void (*callback_)(int, void *)) {
host = host_;
port = port_;
host2 = host2_;
port2 = port2_;
callback = callback_;
tcp_swapServer(); //
weil tcp_connect1() auch einen swap macht
tcp_connect1(NULL);
}
// geaenderte Funktion gegenueber
tcp.c
static void tcp_connect1(void *dummy)
{
tcp_swapServer();
fdServerTmp = socket_async(host, port);
if (fdServerTmp < 0) {
perror("tcp_connect1 socket_async");
after(1000, tcp_connect1, NULL);
return;
}
fpServerTmp = fdopen(fdServerTmp, "a+");
if(NULL == fpServerTmp) {
perror("tcp_connect1 fdopen");
after(1000, tcp_connect1, NULL);
return;
}
after(3000, tcp_connect2, NULL);
}
Ausblick: TCP Client für redundante TCP-Server in
C++
Die C Lösung dual_client.c ist schon sehr ausgefeilt. Leider versagt
die C Lösung wenn gleichzeitig mit mehreren TCP-Servern kommuniziert werden
soll. Durch eine C++ Klasse ist der nötige Schritt zur Verallgemeinerung
möglich.
Das Modul vwait bleibt in C. Es gibt nur einen setitimer() und nur einen
aktiven select() pro Linux Programm, hier kann nichts verallgemeinert
werden. Zwischen dem C Modul vwait und der C++ Klasse TCP2 gibt es einen
Bruch im Programmiermodell. Um diesen Bruch zur überwinden werden die Helper
Funktionen tcp_connect1() und tcp_connect2() benutzt. Die Helper Funktionen
nehmen einen void Zeiger aus dem C Modul entgegen und führen den Aufruf
einer C++ Klassenfunktion aus.
Programm Test
Programm kompilieren mit
gcc -Wall -c vwait.c
g++ -Wall -o dual_clienta dual_clienta.cpp tcp2.cpp vwait.o
Im ersten xterm Fenster eingeben für TCP-Server:
./keepalive_server1 55555
Im zweiten xterm Fenster eingeben für TCP-Server:
./keepalive_server1 55556
Im dritten xterm Fenster eingeben für TCP-Client
./dual_clienta localhost 55555 localhost 55556
Datei
dual_clienta.cpp
#include
<stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include "vwait.h"
#include "tcp2.hpp"
#define SIZE 1400
// Callback Funktion: Daten vom Keyboard verfuegbar
void cb_Kbd(int fdKbd, void *p) {
TCP2 *tcp = (TCP2 *)p;
char buf[SIZE];
fgets(buf, sizeof buf, stdin);
int rv = tcp->puts(buf);
if (-1 == rv) {
fprintf(stderr, "cb_Kbd tcp->puts failed\n");
return;
}
tcp->flush();
}
// Callback Funktion: Daten vom Netzwerk verfuegbar
void cb_Server(int fdServer, void *p) {
TCP2 *tcp = (TCP2 *)p;
char buf[SIZE];
char *rv = tcp->gets(buf, sizeof buf);
if (NULL == rv) {
fprintf(stderr, "cb_Server tcp->gets failed\n");
return;
}
printf("%s", buf);
fflush(stdout);
}
int main(int argc, char *argv[]) {
if (argc != 5) {
fprintf(stderr, "dual_clienta usage: dual_clienta host
port host2 port2\n");
exit(1);
}
const char *host = argv[1];
int port = atoi(argv[2]);
const char *host2 = argv[3];
int port2 = atoi(argv[4]);
vwait_init();
TCP2 tcp;
tcp.open2(host, port, host2, port2, cb_Server);
fileevent_readable(STDIN_FILENO, cb_Kbd, &tcp);
vwait();
// Event Schleife ausfuehren
return 0;
}
Datei
tcp2.hpp
class TCP2 {
const char *host;
int port;
const char
*host2;
// Hostname alternativer TCP Server
int
port2;
// Portnummer alternativer TCP Server
int fdServer;
FILE *fpServer;
void (*callback)(int, void *); // tcp_gets() Callback
Funktion
void swapServer();
void reopen();
public:
void
connect1();
// public wegen C Helper Funktionen
void
connect2();
// public wegen C Helper Funktionen
TCP2();
/**
* Oeffne TCP Verbindung auf TCP-Client Seite fuer redundante
TCP-Server
* @param host_ Hostname passend fuer gethostbyname()
* @param port_ Portnummer
* @param host2_ Hostname alternativer TCP-Server
* @param port2_ Portnummer alternativer TCP-Server
* @param callback Callback-Funktion passend fuer
fileevent_readable()
*/
void open2(const char *host_, int port_, const char *host2_, int
port2_,
void (*callback_)(int, void *));
/**
* Oeffne TCP Verbindung auf TCP-Client Seite mit reopen
* @param host_ Hostname passend fuer gethostbyname()
* @param port_ Portnummer
* @param callback Callback-Funktion passend fuer
fileevent_readable()
*/
void open(const char *host_, int port_, void (*callback)(int, void
*));
/**
* Schreibe C-String buf in Richtung TCP Server (aehnlich
fputs)
* @param buf Zeiger auf 0-terminierten C-String
*
* return -1 bei Fehler, 0 sonst (wie bei fputs)
*/
int puts(const char *buf);
/**
* Sofort aussenden (flush buffer)
*
* return -1 bei Fehler, 0 sonst (wie bei fflush)
*/
int flush();
/**
* Lese C-String bis Zeilenende in buf mit Groesse size vom
TCP-Server
* @param buf Zeiger auf Puffer
* @param size Groesse des Puffers
*
* return NULL bei Fehler, buf sonst (wie bei fgets)
*/
char *gets(char *buf, int size);
/**
* Schliesse TCP Verbindung auf TCP-Client Seite
*
* return -1 bei Fehler, 0 sonst (wie bei fclose)
*/
int close();
};
Datei
tcp2.cpp
#include
<stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include "vwait.h"
#include "tcp2.hpp"
// Helper Funktion um C void Zeiger auf C++ Klassenfunktion Aufruf
umzusetzen
static void tcp_connect1(void *p) {
TCP2 *tcp = (TCP2 *)p;
tcp->connect1();
}
// Helper Funktion um C void Zeiger auf C++ Klassenfunktion Aufruf
umzusetzen
static void tcp_connect2(void *p) {
TCP2 *tcp = (TCP2 *)p;
tcp->connect2();
}
TCP2::TCP2() {
fpServer = NULL;
}
void TCP2::open(const char *host_, int port_, void (*callback_)(int, void
*)) {
host = host2 = host_;
port = port2 = port_;
callback = callback_;
connect1();
}
void TCP2::swapServer() {
const char *hostTmp = host; // Dreier-Tausch
host = host2;
host2 = hostTmp;
int portTmp =
port; //
Dreier-Tausch
port = port2;
port2 = portTmp;
}
void TCP2::open2(const char *host_, int port_, const char *host2_, int
port2_,
void (*callback_)(int, void *)) {
host = host_;
port = port_;
host2 = host2_;
port2 = port2_;
callback = callback_;
swapServer(); // weil
TCP2::connect1() auch einen swap macht
connect1();
}
// TCP Client connect Teil 1: connect() NONBLOCK
void TCP2::connect1() {
swapServer();
fdServer = socket_async(host, port);
if (fdServer < 0) {
perror("TCP2::connect1 socket_async");
after(1000, tcp_connect1, this);
return;
}
after(3000, tcp_connect2, this);
}
// TCP Client connect Teil 2: Pruefen ob Verbindungsaufbau erfolgreich
war
void TCP2::connect2() {
int err = 0;
unsigned len = sizeof err;
getsockopt(fdServer, SOL_SOCKET, SO_ERROR, &err, &len);
if (err != 0) {
fprintf(stderr, "TCP2::connect2 getsockopt: %s\n",
strerror(err));
goto error1;
}
fpServer = fdopen(fdServer, "a+");
if(NULL == fpServer) {
perror("TCP2::connect2 fdopen");
goto error1;
}
fileevent_readable(fdServer, callback, this);
fprintf(stderr, "TCP2::connect2 success host = %s port = %d\n", host,
port);
return;
error1:
::close(fdServer);
// system-call close()
after(1000, tcp_connect1, this);
return;
}
int TCP2::puts(const char *buf) {
if (NULL == fpServer) return -1;
return fputs(buf, fpServer);
}
int TCP2::flush() {
if (NULL == fpServer) return -1;
return fflush(fpServer);
}
// TCP Client nach Fehler aufraeumen
void TCP2::reopen() {
close();
after(1000, tcp_connect1, this);
}
char *TCP2::gets(char *buf, int size) {
char *rv = fgets(buf, size, fpServer);
if (NULL == rv) { // Verbindung
von Gegenseite geschlossen oder Fehler
reopen();
buf[0] = '\0';
}
return rv;
}
int TCP2::close() {
int rv = fclose(fpServer);
fpServer = NULL;
fileevent_readable(fdServer, NULL, NULL);
return rv;
}
TJSON
Grammatik
Bis jetzt wurde der wohl geordnete Zustand von kleinen
Datenelementen (ein C-String, ein unsigned char, eine Uhrzeit) betrachtet.
In diesem Beispiel wird eine kleine Grammatik und ein kleiner Parser
vorgestellt.
Die Grammatik ist eine LL(1)-Grammatik. Die Programmiersprache PASCAL
benutzt eine LL(1) Grammatik. Die Grammatik einer Programmiersprache
definiert was ein Quelltext ohne Syntax-Fehler ist.
Der Parser ist ein Programm welches den Quelltext einliest und nach den
Regeln der Grammatik in seine Bestandteile zerlegt. Typische Bestandteile
sind Sonderzeichen wie < oder =, Schlüsselwörter wie "begin" und
"end" und die vom Programmierer verwendeten Namen für Variablen oder
Prozeduren.
Für die Datenübertragung werden gerne kleine LL(1)-Grammatiken verwendet.
Für eine korrekte LL(1)-Grammatik lässt sich leicht ein korrekter Parser
programmieren. Das Informatik Fachgebiet zum Thema Grammatiken und Parser
ist der Compilerbau.
Grammatik in Strukturierter Sprache
Strukturierte
Sprache ist "Deutsch klar und präzise". Strukturierte Sprache ist schlecht
geeignet die Grammatik zu definieren, aber gut geeignet die Grammatik zu
erklären.
Meldungsformat
Die Meldungen werden in 7-bit ASCII
(ANSI X3.4-1968) kodiert. Jede Meldung besteht aus einem
- Start of Message Zeichen: { (Geschweifte Klammer auf)
- dem Meldungsinhalt
- End of Message Zeichen: }\r\n (Geschweifte Klammer zu, Carrige
Return, Line Feed)
Meldungsinhalt
Der Meldungsinhalt besteht aus einem
oder mehreren Schlüsselwort/Werte Paaren. Ein einzelnes Schlüsselwort/Wert
Paar besteht aus:
- Signal Name (Schlüsselwort) in doppelten Anführungszeichen "
- Zuweisungszeichen : (Doppelpunkt)
- Signal Wert, entweder
-
- eine Zahl in Dezimalschreibweise
- oder eine Zeichenkette in doppelten Anführungszeichen "
Zwischen aufeinander folgenden Schlüsselwort/Werte Paaren steht das
Trennzeichen , (Komma).
Meldungsbeispiel
{"TAG":"LANB","DATE":"16.08.2007","TIME":"11:05:07","SEQ":12,"RWY":1,"CLD":0,"LA1":1,"LA2":0,"CAT1":1,"CATB":0,"CAT2":0,"CAT3":0,"PTA":0}\r\n
Syntax-Diagramm
Das Syntax-Diagramm stellt die
Grammatik graphisch dar.


Die Bilder stammen von der JSON Homepage http://www.json.org
Grammatik in EBNF Schreibweise
Die Grammatik mit
Hilfe einer Grammatik-Beschreibung-Sprache zu definieren ist präzise. Hier
wird der Coco/R Parser Generator verwendet.
/* Tiny JSON - subset of JSON
(RFC4627) */
/* ATG Datei fuer Coco/R LL(1) Parser Generator */
COMPILER tjson
/* Regulaere Ausdruecke (Scanner) */
CHARACTERS
stringChar = ANY - '\"' - '\r' - '\n' .
digit = "123456789" .
TOKENS
STRING = '\"' { stringChar } '\"' .
CONST = '0' | ( digit { '0' | digit} ) .
/* LL(1) Grammatik (Parser) */
PRODUCTIONS
tjson = '{' [ pair { ',' pair } ] '}' '\r' '\n' .
pair = STRING ':' ( STRING | CONST ) .
END tjson.
Der aufmerksame Leser bemerkt die kleinen Unterschiede zwischen den
verschiedenen Beschreibungen der Grammatik. Es wird aber immer die gleiche
Grammatik definiert.
TJSON
Parser Skelett
Aus einer Grammatik kann ein Parser-Generator einen
C-Quelltext erzeugen. Dieses Parser Skelett ist der Ausgangspunkt für den
kompletten Parser. Das Parser Skelett Programm kann schon feststellen ob ein
Quelltext wohl formatiert ist.
void Expect(int n)
{
if (lookahead ==
n)
GetToken();
else {
SynErr(n);
}
}
pair()
{
Expect(TJSON_STRING);
Expect(':');
if (lookahead == TJSON_STRING)
{
GetToken();
} else if (lookahead ==
TJSON_CONST) {
GetToken();
} else
SynErr(256);
}
tjson()
// hier startet der Parser
{
Expect('{');
if (lookahead == TJSON_STRING)
{
pair();
while (lookahead ==
',') {
GetToken();
pair();
}
}
Expect('}');
Expect('\r');
Expect('\n');
// hierher kommt der Parser nur
wenn der Quelltext wohl formatiert war
}
| lookahead |
Variable welche das nächste Symbol (Token) der Eingabe enthält
. |
| GetToken() |
Funktion welche die Variable lookahead mit dem nächsten Symbol der
Eingabe lädt. |
| Expect() |
Funktion welche das erwartete Symbol mit dem gelieferten Symbol
vergleicht und bei Erfolg GetToken() aufruft. |
| SynErr() |
Funktion welche eine Fehlermeldung ausgibt. |
Programm: TJSON Parser mit Fehlerbehandlung
Der
TJSON Parser wird als C++ Programm vorgestellt. Es werden nur die bisher
vorgestellten C++ Erweiterungen Klasse (verallgemeinerte Zugriffsfunktionen)
und Exceptions (Fehler Ausnahme) benutzt. Der TJSON Parser läßt sich auch
als C Programm realisieren - aber bitte glauben Sie mir das es einfacher ist
ein bisschen C++ zu lernen um den Quelltext zu verstehen als sich mit der
Hässlichkeit der C Version auseinander zu setzen.
Programm Test
Programm kompilieren mit
g++ -o tjson_parse_test tjson_parse_test.cpp tjson_parse.cpp
Im xterm Fenster eingeben:
./tjson_parse_test
Datei
tjson_parse.hpp
#ifndef
TJSON_PARSE_HPP
#define TJSON_STRINGLEN 20
#define TJSON_VALUELEN TJSON_STRINGLEN
#define TJSON_STRING 257
#define TJSON_NUMBER 258
#define TJSON_ERR_STRING_TOO_LONG -1
#define TJSON_ERR_NUMBER_TOO_LONG -2
#define TJSON_ERR_UNKNOWN_CHAR -3
#define TJSON_ERR_OPEN_EXPECTED -4
#define TJSON_ERR_CLOSE_EXPECTED -5
#define TJSON_ERR_COLON_EXPECTED -6
#define TJSON_ERR_COMMA_EXPECTED -7
#define TJSON_ERR_CR_EXPECTED -8
#define TJSON_ERR_LF_EXPECTED -9
#define TJSON_ERR_STRING_EXPECTED -10
#define TJSON_ERR_NUMBER_EXPECTED -11
#define TJSON_ERR_SCANNER
-12
#define TJSON_ERR_INVALID_PAIR -13
#define TJSON_ERR_BAD_STRING -14
class TJSON {
int
laChar;
// Scanner Lookahead Zeichen
char yytext[TJSON_STRINGLEN]; // string oder number
int
laToken;
// Parser Lookahead Symbol
char token[TJSON_STRINGLEN]; // enthaelt string
oder number
char string[TJSON_STRINGLEN]; // Zwischenspeicher fuer
call-back Funktionen
const char
*input;
// Class Interface Input Zeiger
void *param;
int (*parse_str)(void *, const char *, const char *); //
Callback Funktion
int (*parse_int)(void *, const char *, const char *); //
Callback Funktion
void GetChar();
int yylex();
void GetToken();
void Expect(int n);
void pair();
void parser();
public:
/** Parse String input nach TJSON LL(1) Grammatik
* @param input_ TJSON Meldung als ASCII C-String
* @param parse_str_ call-back Funktion. Aufruf wenn
String:String Paar
*
Return wert < 0 beendet Parsing
* @param parse_int_ call-back Funktion. Aufruf wenn
String:Integer Paar
*
Return wert < 0 beendet Parsing
* @param param_ Zeiger auf void * Funktionsparameter
*
* return 0 bei Parsing erfolgreich, <0 bei Fehler
*/
int parse(const char *input_,
int (*parse_str_)(void *, const char *, const char *),
int (*parse_int_)(void *, const char *, const char *),
void *param_);
};
#define TJSON_PARSE_HPP
#endif
Datei
tjson_parse.cpp
#include
<cctype>
#include <cstring>
#include "tjson_parse.hpp"
/* ***************************************************** */
/* Scanner */
// Lese neues Zeichen aus dem Eingabe Puffer
void TJSON::GetChar() {
laChar = *input;
if (laChar > 0) { // nicht ueber Stringende
hinauslesen
input++;
}
}
// Scanner Funktion
int TJSON::yylex() {
if (index("{:,}\r\n", laChar)) { // Ein
Zeichen lange Symbole
char ch = laChar;
GetChar();
return ch;
}
if ('\"' == laChar)
{
// TJSON String Konstante
int i = 0;
GetChar();
while (laChar != '\"') {
if ('\r' == laChar || '\n' == laChar || '\0'
== laChar) {
throw TJSON_ERR_BAD_STRING;
}
yytext[i++] = laChar;
GetChar();
if (i+1 >= TJSON_STRINGLEN) {
throw
TJSON_ERR_STRING_TOO_LONG;
}
}
GetChar();
yytext[i] = '\0';
strcpy(token, yytext);
return TJSON_STRING;
}
if (isdigit(laChar))
{
// TJSON Integer Konstante
int i = 0;
yytext[i++] = laChar;
GetChar();
while (isdigit(laChar)) {
yytext[i++] = laChar;
GetChar();
if (i+1 >= TJSON_VALUELEN) {
throw
TJSON_ERR_NUMBER_TOO_LONG;
}
}
yytext[i] = '\0';
strcpy(token, yytext);
return TJSON_NUMBER;
}
throw
TJSON_ERR_UNKNOWN_CHAR; //
Unbekanntes Zeichen
}
/* ***************************************************** */
/* Top Down Parser */
void TJSON::GetToken() {
laToken = yylex();
}
void TJSON::Expect(int n)
{
if (laToken == n)
GetToken();
else {
switch (n) {
case '{': throw
TJSON_ERR_OPEN_EXPECTED; break;
case '}': throw
TJSON_ERR_CLOSE_EXPECTED; break;
case ':': throw
TJSON_ERR_COLON_EXPECTED; break;
case ',': throw
TJSON_ERR_COMMA_EXPECTED; break;
case '\r': throw TJSON_ERR_CR_EXPECTED;
break;
case '\n': throw TJSON_ERR_LF_EXPECTED;
break;
case TJSON_STRING: throw
TJSON_ERR_STRING_EXPECTED; break;
case TJSON_NUMBER: throw
TJSON_ERR_NUMBER_EXPECTED; break;
default: throw
TJSON_ERR_SCANNER; break;
}
}
}
void TJSON::pair()
{
Expect(TJSON_STRING);
strcpy(string, token);
Expect(':');
if (TJSON_STRING == laToken) {
GetToken();
int rv = (*parse_str)(param, string, token);
if (rv < 0) throw rv;
} else if (TJSON_NUMBER == laToken) {
GetToken();
int rv = (*parse_int)(param, string, token);
if (rv < 0) throw rv;
} else
throw TJSON_ERR_INVALID_PAIR;
}
void TJSON::parser()
{
Expect('{');
if (TJSON_STRING == laToken) {
pair();
while (',' == laToken) {
GetToken();
pair();
}
}
Expect('}');
Expect('\r');
Expect('\n');
}
/* ***************************************************** */
/* Interface */
int TJSON::parse(const char *input_,
int (*parse_str_)(void *, const char *, const char *),
int (*parse_int_)(void *, const char *, const char *),
void *param_) {
param = param_;
input = input_;
parse_str = parse_str_;
parse_int = parse_int_;
try {
GetChar(); // Init
Scanner
GetToken(); // Init Parser
parser();
return 0;
}
catch (int err) {
return err;
}
}
Datei
tjson_parse_test.cpp
#include
<cstdio>
#include "tjson_parse.hpp"
// Parser call-back. Aufruf bei String:String Paaren
int cb_parse_str(void *p, const char *key, const char *val) {
printf("\tcb_parse_str %s %s\n", key, val);
return 0;
}
// Parser call-back. Aufruf bei String:Integer Paaren
int cb_parse_int(void *p, const char *key, const char *val) {
printf("\tcb_parse_int %s %s\n", key, val);
return 0;
}
int main() {
const char *testinput[] = {
"{\"TAG\":\"LANB\",\"RWY\":1}\r\n",
"{\"TAG\":\"LANffffffffffffffffB\",\"RWY\":1}\r\n",
"{\"TAG\":\"LANB\",\"RWY\":19999999999999999}\r\n",
"{\"TAG\":\"LANB\",.\"RWY\":1}\r\n",
"\"TAG\":\"LANB\",\"RWY\":1}\r\n",
"{\"TAG\":\"LANB\",\"RWY\":1\r\n",
"{\"TAG\":\"LANB\",\"RWY\"1}\r\n",
"{\"TAG\":\"LANB\":\"RWY\":1}\r\n",
"{\"TAG\":\"LANB\",\"RWY\":1}\n",
"{\"TAG\":\"LANB\",\"RWY\":1}\r",
"{\"TAG\":\"LANB\",2:1}\r\n",
"{\"TAG\":\"LANB\",\"RWY\":0x11}\r\n",
"{\"TAG\"::\"LANB\",\"RWY\":1}\r\n",
"{{\"TAG\":\"LANB\",\"RWY\":1}\r\n",
"{\"TAG\"\":\"LANB\",\"RWY\":1}\r\n",
"{\"TAG\":\"LANB\",,\"RWY\":1}\r\n",
"{\"TAG\":\"LANB\",\"RWY\":1}}\r\n",
"{\"TAG\":\"LANB\",\"RWY\":1}\r\r\n",
"\n{\"TAG\":\"LANB\",\"RWY\":1}\r\n",
"{\"TAG:\"LANB\",\"RWY\":1}\r\n",
"{\"TAG\":\"LANB,\"RWY\":1}\r\n",
"{\"TAG\":\"LANB\",\"RWY\":1",
"{\"TAG\":\"LANB\",\"RWY",
"{\"TAG\":\"LANB\",\"RWY:1}\r\n",
"{\"TAG\r\":\"LANB\",\"RWY\":1}\r\n",
"{\"TAG\":\"LANB\n\",\"RWY\":1}\r\n",
"{\"TAG\":\"LANB\",\"RWY\":1\"}\r\n",
NULL // testinput vector Ende
};
int i;
for (i = 0; testinput[i] != NULL; ++i) {
printf("Input: %s", testinput[i]);
TJSON tjson;
int rv = tjson.parse(testinput[i], cb_parse_str,
cb_parse_int, NULL);
printf("TJSON::parse() returns %d\n\n", rv);
}
return 0;
}
Das Parser Interface benutzt call-back Funktionen. Butler W. Lampson
(erhielt 1992 den ACM Turing Award) empfiehlt dieses Vorgehen in seinem
Artikel Hints for
computer system design von 1983.
Programm: Datenstrom nach Datensatz
Umwandlung
Der Parser liest die Daten in der externen ASCII
Darstellung (representation). Für die weitere Verarbeitung im C Programm ist
eine internen Darstellung als struct oder class besser geeignet. Mit Hilfe
der Parser call-back Funktionen wird dieser letzte Schritt der Datenstrom
nach Datensatz Umwandlung ausgeführt.
Programm Test
Programm kompilieren mit
g++ -o tjson_parse_test2 tjson_parse_test2.cpp tjson_parse.cpp
string_s.c
Im xterm Fenster eingeben:
./tjson_parse_test2
Datei
tjson_parse_test2.cpp
#include
<cstdio>
#include <cstdlib>
#include <cstring>
#include "tjson_parse.hpp"
#include "string_s.h"
typedef struct {
char tag[10];
char date[11];
int rwy;
} LIGHTS; //
Datensatz
// Parser call-back. Aufruf bei String:String Paaren
int cb_parse_str(void *p, const char *key, const char *val) {
LIGHTS *lights = (LIGHTS *)p;
if (0 == strcmp("TAG", key)) {
strcpy_s(lights->tag, sizeof lights->tag, val);
return 0;
}
if (0 == strcmp("DATE", key)) {
strcpy_s(lights->date, sizeof lights->date,
val);
return 0;
}
return -101;
}
// Parser call-back. Aufruf bei String:Integer Paaren
int cb_parse_int(void *p, const char *key, const char *val) {
LIGHTS *lights = (LIGHTS *)p;
if (0 == strcmp("RWY", key)) {
lights->rwy = atoi(val);
return 0;
}
return -102;
}
int main() {
const char *testinput[] = {
"{\"TAG\":\"LANB\",\"DATE\":\"20.01.2008\",\"RWY\":1}\r\n",
"{\"MAG\":\"LANB\",\"DATE\":\"20.01.2008\",\"RWY\":1}\r\n",
"{\"TAG\":\"LANB\",\"DATE\":\"20.01.2008\",\"rWY\":1}\r\n",
NULL // testinput vector Ende
};
int i;
for (i = 0; testinput[i] != NULL; ++i) {
printf("Input: %s", testinput[i]);
LIGHTS lights = { "", "", -1};
TJSON tjson;
int rv = tjson.parse(testinput[i], cb_parse_str,
cb_parse_int, &lights);
if (0 == rv) {
printf("TJSON::parse() found tag=%s, date=%s,
rwy=%d\n",
lights.tag, lights.date,
lights.rwy);
}
printf("TJSON::parse() returns %d\n\n", rv);
}
return 0;
}
Prozesspriorität
Die Prozesspriorität legt fest wie
wichtig ein Prozess für den Computer sein soll. Wichtigere Prozesse werden
bevorzugt bedient.
Alle Benutzer-Prozesse laufen mit der Prozesspriorität 0. Für den Scheduler
(Prozessumschalter) im Linux Kernel sind dadurch alle Benutzer-Prozesse
gleich. Prozesse welche vom Superuser gestartet werden können eine bessere
Prozesspriorität erhalten.
Mit dem system-call setpriority() kann die Prozesspriorität gesetzt werden.
Dabei bedeutet 19 die unwichtigste Priorität und -20 die wichtigste
Priorität. Einige Betriebssystem-Prozesse (Daemons) arbeiten mit der
Priorität 19 (ksoftirqd), andere Daemons arbeiten mit -2 (ipw3945d) bis -5
(kthreadd).
Ein bevorzugter Benutzer-Prozess sollte deshalb eine Prozesspriorität von -1
benutzen.
Übung
1
Ändern Sie setitimer.c nach setitimer2.c. Bringen Sie am Anfang von
main() den setpriority() Aufruf unter. Die nötige Include Datei ist.
#include
<sys/resource.h>
int rv =
setpriority(PRIO_PROCESS, 0, -1);
if (-1 == rv)
{
perror("setitimer2
setpriority");
}
Testen Sie das Programm mit dem Aufruf
./setitimer2
und mit dem Aufruf
sudo ./setitimer2
Was ist der Unterschied?
Übung
2
Für eine Zeitmessung im Programm erweitern Sie setitimer2.c nach
setitimer3.c. Vor der for() Schleife schreiben Sie:
struct timeval tv0;
gettimeofday(&tv0,
NULL);
Nach der for() Schleife schreiben Sie:
struct timeval tv1;
gettimeofday(&tv1,
NULL);
long long t0 = 1000000 *
tv0.tv_sec + tv0.tv_usec;
long long t1 = 1000000 *
tv1.tv_sec + tv1.tv_usec;
printf("\nLaufzeit = %lld
usec\n", t1 - t0);
Testen Sie wieder der Programm mit beiden Aufrufen:
./setitimer3
sudo ./setitimer3
Gibt es einen Unterschied?
Übung
3
Versuchen Sie den Test auch wenn die CPU stark belastet ist. Für die
CPU Belastung benutzen Sie in einem zweiten xterm Fenster folgendes Kommando
zur Berechnung der Fakultät von 123456 mit dem bc "Taschenrechner":
bc <fac.bc
Bemerkung: Für Computer mit 2 CPU-Cores muss zweimal bc aufgerufen werden
für volle .
Die Datei fac.bc hat den Inhalt
# fac.bc
# BC Skript zum Berechnen der
Fakultaet
define f (x) {
if (x <= 1) return
(1); # der Sonderfall f(1) = 1
return (x *
f(x-1)); # der Normalfall rekursive
Berechnung
}
f(123456);
Call
Tree, Call Trace, Backtrace
Ein Call Tree ist die Aufrufreihenfolge
der Unterprogramme (Prozeduren, Funktionen) wie sie aus dem Quelltext
ermittelt werden. Programme wie cflow (Linux), cflow (MS-Windows) oder
calltree erstellen
entsprechende Dokumente. Ein Call Trace zeigt die Aufrufreihenfolge des
laufenden Programmes. Der GNU C compiler unter Linux unterstützt einen
backtrace
ohne Änderung des Quelltextes. Die etrace Bibliothek benutzt diese GCC
Fähigkeit. Der Quelltext muss zusammen mit etrace compiliert werden.
Mit Hilfe des Präprozessors kann für jeden C oder C++ Compiler ein Call
Trace erzeugt werden. Das Makro fn() realisiert den grössten Teil der call
trace Funktion. Jeder Unterprogrammaufruf wird durch dieses Makros
erweitert. Vor dem Unterprogrammaufruf wird die Prozedur __call()
aufgerufen, nach dem Unterprogrammaufruf wird __ret() aufgerufen. Die erste
Hilfsprozedur protokolliert den Namen des Unterprogrammes, die Parameter
sowie die Stelle im Quelltext wo der Unterprogrammaufruf erfolgt. Die
Aufruftiefe (nesting level) wird durch __call() erhöht. Die Prozedur __ret()
erniedrigt die Aufruftiefe wieder. Der folgende C Quelltext zeigt das Makro,
die Hilfsprozeduren und den Einsatz in einem kleinen Demo-Programm mit der
rekursiven Funktion fibonacci().
Das Makro fn() enthält das Statement Trennzeichen ; (Semikolon). Das Makro
funktioniert nur dann korrekt, wenn if(), else, while(), do und for()
zusammen mit { und } verwendet werden. Die geschweiften Klammern umschließen
einen Block
(compound statement). Die Zeile int rv
= fibonacci(n); wird mit dem CallTrace Makro fn() zu der Zeile
fn(int rv = fibonacci(n)); .
Diese, für einen C-Programmierer ohne Makro-Erfahrung fehlerhaft aussehene
Zeile, wird fehlerfrei compiliert. Der Compiler sieht den Quelltext
__call(); int rv = fibonacci(n);
__ret(); .
/* dieser Teil steht in callTrace.h
*/
// CallTree Makro fuer Funktionsaufruf (mit oder ohne Returnwert)
// vor Prozeduraufruf wird __call() aufgerufen, danach wird __ret()
aufgerufen
#define fn(func) __call(#func, __FILE__, __LINE__); func;
__ret()
/* dieser Teil steht in callTrace.c */
#include <stdio.h>
#include <string.h>
#ifdef _WIN32
#define FILESEP '\\'
#else
#define FILESEP '/'
#endif
// Groesse CallTree Speicher in Zeilen
#define MAXCALLTRACE (1 << 6) //
nur 2er Potenzen erlaubt
typedef struct {
char *proc, *file;
int depth, line;
} CALLTRACE;
static CALLTRACE ct[MAXCALLTRACE];
static int last = 0;
static int callDepth = 0;
// Hilfsprozedur Logging von Subprogramm Abstieg
void __call(char *proc, char *file, int line) {
ct[last].proc = proc;
ct[last].file = file;
ct[last].depth = callDepth++;
ct[last].line = line;
last = (last + 1) & (MAXCALLTRACE -
1); // entspricht modulo MAXCALLTRACE
}
// Hilfsprozedur Subprogramm Aufstieg
void __ret() {
--callDepth;
}
// CallTrace Modul initialisieren
void callTraceInit() {
int i;
for (i = 0; i < MAXCALLTRACE; ++i) {
ct[i].proc = NULL;
}
last = 0;
callDepth = 0;
}
// CallTrace ausgeben
void callTracePrint(FILE *fp) {
// suche Anfang
int cnt, ndx = last;
for (cnt = 0; cnt < MAXCALLTRACE; ++cnt) {
int newNdx = (ndx - 1) &
(MAXCALLTRACE - 1);
if (newNdx == last || NULL ==
ct[newNdx].proc ) {
break;
}
ndx = newNdx;
}
// Ausgabe
int i;
for (i = 0; i < cnt; ++i) {
char *basename =
strrchr(ct[ndx].file, FILESEP);
if (NULL == basename) {
basename
= ct[ndx].file;
} else {
++basename; // FILESEP nicht mit
ausgeben
}
int j;
for (j = 0; j < ct[ndx].depth;
++j) {
fprintf(fp, " ");
}
fprintf(fp, "%s at %s:%d\n",
ct[ndx].proc, basename, ct[ndx].line);
ndx = (ndx + 1) &
(MAXCALLTRACE - 1);
}
}
/* hier beginnt das Demo-Programm */
// Fibonacci Folge
int fibonacci(int n) {
if (0 == n) {
return 0;
} else if (1 == n) {
return 1;
} else {
fn(int rv = fibonacci(n -
1));
fn(rv += fibonacci(n - 2));
return rv;
}
}
int main (int argc, char *argv[]) {
printf("CallTrace for C by Andre Adrian\n\n");
callTraceInit();
int n = 5;
fn(int rv = fibonacci(n));
// CallTrace einer
Funktion
printf("fibonacci(%d) = %d\n", n, rv);
fn(callTracePrint(stderr));
// CallTrace einer
Prozedur
getchar();
return 0;
}
Das Programm cflow liefert für die Datei callTrace.c den Flowchart:
main() <int main (int argc,char
*argv[]) at callTrace.c:108>:
printf()
callTraceInit() <void callTraceInit () at
callTrace.c:54>:
fn()
fibonacci() <int fibonacci (int n) at
callTrace.c:96> (R):
fn()
fibonacci() <int fibonacci
(int n) at callTrace.c:96> (recursive: see 5)
call()
callTracePrint() <void callTracePrint (FILE *fp) at
callTrace.c:64>:
strrchr()
fprintf()
Das Programm callTrace analysiert das Demo-Programm, die rekursive
Berechnung der Fibonacci-Zahl für das Argument 5:
CallTrace for C by Andre Adrian
fibonacci(5) = 5
int rv = fibonacci(n) at callTrace.c:113
int rv = fibonacci(n - 1) at callTrace.c:102
int rv = fibonacci(n - 1) at
callTrace.c:102
int rv = fibonacci(n - 1)
at callTrace.c:102
int rv =
fibonacci(n - 1) at callTrace.c:102
rv +=
fibonacci(n - 2) at callTrace.c:103
rv += fibonacci(n - 2) at
callTrace.c:103
rv += fibonacci(n - 2) at callTrace.c:103
int rv = fibonacci(n - 1)
at callTrace.c:102
rv += fibonacci(n - 2) at
callTrace.c:103
rv += fibonacci(n - 2) at callTrace.c:103
int rv = fibonacci(n - 1) at
callTrace.c:102
int rv = fibonacci(n - 1)
at callTrace.c:102
rv += fibonacci(n - 2) at
callTrace.c:103
rv += fibonacci(n - 2) at callTrace.c:103
callTracePrint(stderr) at callTrace.c:115
Variable Trace
Ähnlich wie das Makro fn() kann mit
einem Makro let() ein Variable Trace realisiert werden. Der Variable Trace
zeigt den Wert einer Variable während das Programm läuft.
Ist
fehlerfreie Software möglich?
Die Antwort lautet ja, unter gewissen
Randbedingungen. Softwarequalität entsteht durch Erkennen der Sonderfälle
und korrekte Behandlung der Sonderfälle. Bei den vorgestellten Programmen
sind zwei Arten von Sonderfällen nicht berücksichtigt worden:
- write() system-call liefert Fehler
- IP fragmentation bei read()
Diese Sonderfälle sind absichtlich nicht aus-programmiert worden. Es
werden auch keine Tests für diese Sonderfälle angegeben. Die Programme
werden beim Auftreten dieser Sonderfälle Fehler zeigen gemäß dem Sinnspruch:
Alles was getestet wird funktioniert, alles was nicht getestet wird
funktioniert nicht.
Eine zweite Quelle für versteckte Fehler sind die Brüche im
Programmiermodell. Das Betriebssystem Linux ist in C programmiert. Die
Schnittstelle zum Betriebssystem sind C system-calls. Wird die Applikation
in C programmiert gibt es keinen Bruch zwischen
Applikation-Programmiersprache und Betriebssystem-Programmiersprache. Schon
die Verwendung der string Klasse der Programmiersprache C++ schafft einen
solchen Bruch. Ein Dateiname als Variable der Klasse string muss für einen
Betriebssystem Aufruf in einen C-String umgesetzt werden. Die Umsetzung in
die andere Richtung ist auch nötig, z.B. beim Abfragen der Dateinamen in
einem Verzeichnis über den Betriebssystem Aufruf readdir().
Die Datenkommunikation zwischen zwei Computern geht ebenfalls mit einem
Bruch im Programmiermodell einher. Ein einfaches Beispiel sind die htons()
und ntohs() Aufrufe um die Port-Nummer von Host Byte Order (CPU eigenen
Integer Format) nach Network Byte Order (von IP verlangtes Integer Format)
umzuwandeln.
Richtig deutlich wird der Bruch im Programmiermodell bei Lösungen wie
CORBA. Hier gibt es eine
eigene Programmiersprache IDL zum Beschreiben der Datensätze. Ein IDL
Compiler erzeugt aus der Datensatzbeschreibung einen Quelltext für die in
der Applikation verwendeten Programmiersprache damit der
Applikationsprogrammierer sich nicht mit den Details der Umwandlung von
Datensätzen zwischen interner und externer Darstellung auseinander setzen
muss. Leider muss sich der Applikationsprogrammierer mit den Details des IDL
Compilers und dem vom IDL Compiler produzierten Quelltext herum plagen. Für
manche Programmierer ist das schlimmer als das eigentliche Problem!
Die hier vorgestellte TJSON Grammatik leidet auch unter dem Problem des
Unterschiedes der externen Darstellung der Daten durch einen ASCII String
und der sinnvollen internen Darstellung der Daten durch eine struct oder
class. Für TJSON gibt es keinen IDL Compiler, der Programmierer muss die
entsprechenden Funktionen für die Umwandlung selbst schreiben.
Neuer als CORBA ist Web
Service. Die Idee hinter Web Service ist älter. Es werden HTTP Meldungen
zwischen Service-Nutzer-Computer und Service-Anbieter-Computer ausgetauscht.
Durch genaue Spezifikation (SOAP, SAML, Semantic Web
Services, ...) der Nutzdaten soll Web Service die Integrationsfähigkeit
von Computersystemen auf eine höhere Entwicklungsstufe bringen.
Wenn alle nötigen Sonderfälle aus-programmiert werden und wenn die Brüche an
der Schnittstelle Applikation zu Betriebssystem und Applikation zum Netzwerk
und über das Netzwerk zur nächsten Applikation sinnvoll behandelt werden
dann entsteht fehlerfreie Software mit noch immer einer Einschränkung.
Die letzte Einschränkung ergibt sich aus der Sonderfall-Behandlung. Die
vorgestellten Methoden truncation (Abschneidung) und saturation (Sättigung)
sind sinnvoll. Diese Methoden lösen aber nicht das grundlegende Problem: Die
im Programm vorgesehene Speichergröße reicht für das Datum nicht aus. Eine
Programmiersprache mit dynamischen Variablen-Größen ist nur scheinbar die
Lösung. Irgendwann ist der komplette Arbeitsspeicher aufgebraucht und dann
hat auch eine solche Applikation Probleme.
Zum Abschluss bleibt nur folgender Rat: Die verwendete Programmiersprache
ist zweitrangig. Wichtiger ist eine robuste Programmierung im Kleinen wie im
Großen. Die relevanten Sonderfälle müssen während dem System Design erkannt
werden und müssen konsequent aus-programmiert werden. Für die Wartbarkeit
des Systems ist die Untergliederung der Applikation in sinnvolle
Software-Schichten (software layers, Abstraktion-Ebenen, Module, Klassen)
sehr wichtig, vielleicht die wichtigste Entscheidung überhaupt die während
dem System Design getroffen wird.
Für die Programmierung in C++ ist RAII
(Resourcenbelegung ist
Initialisierung) eine sehr wichtige Programmiertechnik.
Was
die theoretische Informatik noch nicht weiss
Wenn die theoretische
Informatik für ein Problem keine Lösung kennt, dann kann ein System für
dieses Problem keine fehlerfreie Software-Lösung liefern. Dieser
Zusammenhang zwischen Theorie und Praxis sollte einleuchten. Leider bemerkt
Tony Hoare in seiner Turing Award
Rede 1980 treffend: "Almost anything in software can be implemented,
sold, and even used given enough determination. There is nothing a mere
scientist can say that will stand against the flood of a hundred million
dollars."
Das
Problem der letzten Meldung
Im TCP state diagram ist die ACK Meldung die
letzte Meldung beim TCP Verbindungs-Abbau. Sie bringt den ACK empfangenden
Computer vom Zustand LAST_ACK in den Zustand CLOSED. Fehlt diese letzte
Meldung aufgrund eines kurzzeitigen Netzwerk-Ausfalles, so hat der eine
Computer den TCP Verbindungs-Abbau komplett durchgeführt, der andere
Computer aber nicht.
Das Problem der letzten Meldung wird üblicherweise mit einem Time-out
entschärft. Der system-call setsockopt() mit dem Parameter SO_REUSEADDR
ändert das Time-out Verhalten des TCP-Stacks.
Das
Split-Brain (Split-Network) Problem
Im Fault Tolerant CORBA
Dokument 01-09-29 der OMG.org wird in aller Einfachheit gesagt: "Network
partitioning faults separate the hosts of the system into two or more sets,
the hosts of each set being able to operate and to communicate within that
set but not with hosts of different sets. The current state-of-the-art does
not provide an adequate solution to network partitioning faults."
Natürlich leidet nicht nur Fault Tolerant CORBA unter dem Split-Brain oder
Split-Network Problem. Die Lösung ist üblicherweise ein Eingriff durch das
Wartungspersonal. Die Applikationen in einem der beiden Split-Networks
werden komplett gestoppt. Dann werden die beiden Split-Networks wieder
vereint. Im letzten Schritt werden die gestoppten Applikationen neu
gestartet.
Eine automatische Lösung für das Split-Network Problem kann mit einem
ähnlichen Algorithmus wie für die Ethernet Kollisionsauflösung liegen.
Nachdem ein Split-Network wieder zusammengefügt wird, erkennen die
Rechner-Knoten das zuviele Hosts aktiv sind, diese Phase entspricht der
Kollisionserkennung im Ethernet. In der zweiten Phase berechnet jeder Host
eine Zufallszahl. Diese Zufallszahl bestimmt wann der Host seinen Anspruch
auf die "Herrscher-Krone" anmeldet. Der Host mit der kleinsten Zufallszahl
meldet sich zuerst und wird "Herrscher".
Die Oracle Datenbank behandelt das Split-Brain Problem anders. Nachdem die
beiden durch Split-Brain getrennten Netzwerke wieder Datenaustausch
miteinander haben werden die "Untertanen" der einzelnen "Herrscher" gezählt.
Der "König" mit den meisten "Untertanen" bleibt "König", das andere "König"
wird erschossen. Dabei sind die beiden "Königen" natürlich die
Cluster-führenden Server und die "Untertanen" die Clients. Egal wie das
Split-Brain Problem gelöst wird, durch Eingriff des Wartungspersonals, durch
Zufallsentscheidung oder durch "Voting" es kommt zu Datenverlust. Dieser
Datenverlust ist aber immer noch besser als ein "Bürgerkrieg" zwischen
rivalisierenden "Königen" im Königreich Binary.
Historie von C
Im Jahr 1978 erschien das Buch "The
C Programming Language" von Brian W. Kernighan und Dennis M. Ritchie. Das
Betriebssystem UNIX und die Programmiersprache C sind eigentlich ungewollte
Entwicklungen die zwischen 1971 und 1973 begonnen haben. Eigentlich wollte
Bell Labs (AT&T) das Betriebssystem Multics mit der Programmiersprache
PL/I (PL/1) einsetzen. Aber 1969 ist Bell Labs aus der Multics Entwicklung
ausgestiegen. Multics und PL/I sind Riesen, UNIX und C sind Zwerge. Heute
leben die Zwerge als Linux und GCC noch prächtig und die Riesen sind schon
lange tot und vergessen. Im Jahr 1983 erschien das Berkeley sockets
application programming interface (socket-API) als Teil von 4.2BSD UNIX.
Damit hat TCP/IP und das weltweite Internet seinen Siegeszug begonnen. Im
Jahr 1985 erschien "The C++ Programming Language" von Bjarne Stroustrup. Mit
C++ wurde aus dem Zwerg C ein Riese. Wie bei anderen
Riesen-Programmiersprachen wie Algol 68 oder PL/1 kann der Programmierer in
der Komplexität der Programmiersprache C++ grandios untergehen.
Im Jahr 1989 erschien der ANSI-C Standard. Dadurch wurde der Sprachumfang
von C und der C-Bibliothek genauer definiert und die Funktionsprototypen
offiziell in den C Sprachumfang aufgenommen. Im Jahr 2008 ist C ungefähr 35
Jahre alt. Heute ist C out und andere Programmiersprachen wie Java sind in.
Leider machen die Java Jünger die gleiche Erfahrung wie die Ada, PL/I oder
Algol Programmierer vor ihnen: In jeder Programmiersprache kann man
fehlerhafte Programme schreiben. Ein Array Range Check und ein Garbage
Collector fangen vielleicht einige Fehler, aber nicht alle. Deshalb geht die
Suche nach der perfekten Programmiersprache weiter. Bis jetzt hat nur die
nutzlose Programmiersprache SIMPLE mit ihren drei Wörtern "begin", "stop"
und "end" dieses Ziel erreicht. Bemerkung: Der Web-Link zu SIMPLE ist tot.
Heute gibt es eine echte Programmiersprache SiMPLE welche nicht nutzlos
ist.
C war für seine Zeit und ist auch heute noch ein wichtiger Meilenstein auf
dieser Suche nach dem heiligen Gral der
Programmiersprachen.
Danksagung
Die Danksagung geht an die Personen
welche die Werkzeuge geschaffen haben mit denen dieses Dokument erzeugt
wurde:
- gcc Compiler von Richard Stallman und
allen anderen Leuten der FSF
- Linux Betriebsystem von Linus Torvalds und allen
anderen Linux Kernel Leuten
- Openoffice Textverarbeitung von Marco Börries und
allen anderen Leuten von Staroffice, Openoffice, Libreoffice
- Seamonkey Composer von Marc Andreessen und
allen anderen Leuten von Mosaic, Netscape, Mozilla
- und alle anderen die bis jetzt noch nicht erwähnt wurden für ihre
Werkzeuge (man, nedit, Coco/R, indent, cflow, cscope, tidy, valgrind,
strace, lsof ...)
Weiterführende Literatur
TCP Programmierung in
C:
W. Richard Stevens, Programmieren von UNIX-Netzwerken, 2.Auflage, 2000, Carl
Hanser Verlag
Jürgen Wolf, Linux-UNIX-Programmierung, 2.Auflage, 2005, Galileo
Computing
C Programmiersprache:
Jürgen Wolf, C von A bis Z, 2. Auflage, 2006, Galileo Computing
Kernighan, Ritchie, Programmieren in C, 2. Ausgabe, 1990, Prentice-Hall
Kernighan, Pike, The Practice of Programming, 1999, Addison-Wesley
C++ Programmiersprache:
Jürgen Wolf, C++ von A bis Z, 2006, Galileo Computing
Bjarne Stroustrup, Die C++ Programmiersprache, 2000, Addison Wesley
Die Bücher von Jürgen Wolf sind als Open-Books im Internet lesbar bei
http://www.pronix.de
http://www.galileocomputing.de/openbook/c_von_a_bis_z
Die Online Dokumentation über die GNU libc (C-Bibliothek) ist sehr
ausführlich, aber leider in Englisch.
http://www.gnu.org/software/libc/manual
Die Bücher von Brian W. Kernighan sind sehr empfehlenswert.

Brian W. Kernighan; Programming in C: A
Tutorial; Bell Laboratories; 1974
Kernighan, Plauger; Software Tools; Addison-Wesley; 1976
Brian W. Kernighan, Dennis Ritchie; The C Programming Language; 1978,
1988
Brian W. Kernighan, Dennis Ritchie; Programmieren in C; Hanser Fachbuch;
1983, 1990
Kernighan, Pike; The UNIX Programming Environment; Prebtice Hall; 1984
Aho, Kernighan, Weinberger; The AWK Programming Language; Addison-Wesley;
1988
Kernighan, Pike; The Practice of Programming; Addison-Wesley; 1999
Über
der Autor
Prozessdatenverarbeitung unter C hat für den Autor begonnen
mit dem Lattice C
Compiler. Das ist nun schon einige Jahre her. Heute sind gcc und g++
unter Linux die Werkzeuge. Nach 20 Jahren PDV unter C ist der Autor fest
entschlossen die nächsten 20 Jahre weiterhin PDV unter C zu machen.
Natürlich sind die Systeme von 2007 anders als die Systeme von 1987 und das
heutige C ist ein C++. Aber das Message Sequence
Chart und das State Diagram sind immer noch die besten Werkzeuge des
System Designers. "Nichts ist praktischer als eine passende Theorie" sagte
der Professor und ging.