Liebe Erstsemester Studenten der Informatik! Wahrscheinlich haben Sie
eine Vorlesung mit dem Namen "Algorithmen und Datenstrukturen". Und
wahrscheinlich liegt die Durchfallquote in der Klausur zwischen 70% und 80%.
Ohne Lernwillen und Fleiß werden Sie die Klausur niemals schaffen und ihr
Informatik-Studium ist schnell zu Ende. Diese Internet-Seite möchte Ihnen
beim Lernen helfen. Sehen Sie es als eine Vorbereitung auf die Vorlesung an.
Warum will ich ihnen helfen? Ich bin selbst Informatiker und habe mein
Studium 1988 begonnen. Das Studium war seinerzeit hart. Aber heute ist es
dank Bachelor gemein.
Bemerkung: Wenn ich Studenten schreibe meine ich natürlich Studentinnen und
Studenten. Es ist mir nur zu umständlich dies immer auszuschreiben. Deshalb
liebe Studentinnen: Bitte fühlen Sie sich bei dem Wort Studenten mit
angesprochen!
Als Student besitzen Sie bestimmt einen Computer, wahrscheinlich einen
Laptop. Und höchstwahrscheinlich benutzen Sie das Betriebssystem MS-Windows.
Für die Vorlesung "Algorithmen und Datenstrukturen" und für diese
Internet-Seite benötigen Sie aber das Betriebssystem Linux. Warum?
MS-Windows ist ein Spielzeug und Linux ist ein Werkzeug. Dies ist natürlich
meine Informatiker-Meinung und diese ist oft nicht in Übereinstimmung mit
der DAU-Meinung (DAU=Dümmster Anzunehmender User).
Neben dem Betriebssystem Linux benötigen Sie noch mindestens einen Editor
und einen C-Compiler. Der C-Compiler für Linux ist (fast) immer der GNU
C-Compiler gcc. Der Editor ist Geschmackssache. Einige Oldtimer benutzen den
vi Editor, denn "wenn nichts geht, vi geht" (vi läuft auch ohne
graphische Benutzeroberfläche). Andere benutzen den EMACS (Eight
Megabytes And Constantly Swapping). Für einen GNOME-Desktop Linux ist
gedit der mitgelieferte Editor, für einen KDE-Desktop Linux ist es
kwrite. Einige Programmierer empfehlen geany. Dieser Editor
malt den C-Quelltext schön bunt. Eine extreme Lösung ist die Installation
von wine, dem MS-Windows Emulator für Linux, und dann die Installation von
Notepad++ mit Hilfe von
winetricks. Ich selbst
benutze den total aus der Mode gekommenen nedit (Nirwana Editor).
Unter Ubuntu Linux (getestet mit Version 14.04) lässt sich nedit leicht
installieren - da scheinen noch andere Ewig-Gestrige unterwegs zu sein.
Neben dem absoluten Minimum Betriebssystem, Editor und Compiler sind weitere
Werkzeuge nützlich. Unter Linux sind die man-pages eine prima
Informationsquelle. Wie war das noch einmal mit der printf() Funktion?
Einfach man 3 printf eintippen und schon wird ihnen geholfen. Zwei
Werkzeuge die der Professor üblicherweise verschweigt und die auch in der
Übung nicht vorgestellt werden sind der Pretty-Printer indent und der
Debugger ddd. Der Debugger ist das Werkzeug um "mittelschwere"
Programmfehler zu finden. Der Pretty-Printer gibt dem C-Quelltext eine
standardisierte Formatierung. Warum ist das hilfreich? Der Mensch ist ein
Gewohnheitstier. Ich kann nach meinem Geschmack "korrekt" formatierten
Quelltext schnell lesen und verstehen. Ist der Quelltext meiner Meinung nach
"falsch" formatiert, dann lasse ich durch den Pretty-Printer die
Formatierung korrigieren. In den folgenden Listings benutze ich übrigens
indent -i4 -nut -kr, d.h. die Einrückung ist vier Leerzeichen, die
Einrückung erfolgt mit Leerzeichen und die Formatierung ist nach dem
Kernighan-Ritchie Standard.
Eine graphische Benutzeroberfläche ist etwas feines. Ein bisschen
Mäuse-Schubsen, ein wenig Klicken und schon ist die Arbeit getan. Früher, in
der Computer Steinzeit, gab es nur die Kommandozeile. Und auch heute sollte
der Informatiker noch mit der Kommandozeile arbeiten können. Was ist nun die
Kommandozeile unter einer graphischen Oberfläche? Es ist ein Fenster in das
man Befehle an das Betriebssystem eingeben kann. Ein solchen Befehl ist
gcc -g -O0 -Wall -o list_delete_value list_delete_value.c, Mit
diesem Befehl wird die Quelltextdatei list_delete_value.c in die ausführbare
Datei list_delete_value übersetzt mit Optionen die ein Debuggen des
Programms erlauben. Es gibt unter Linux etliche Kommandozeilen-Programme,
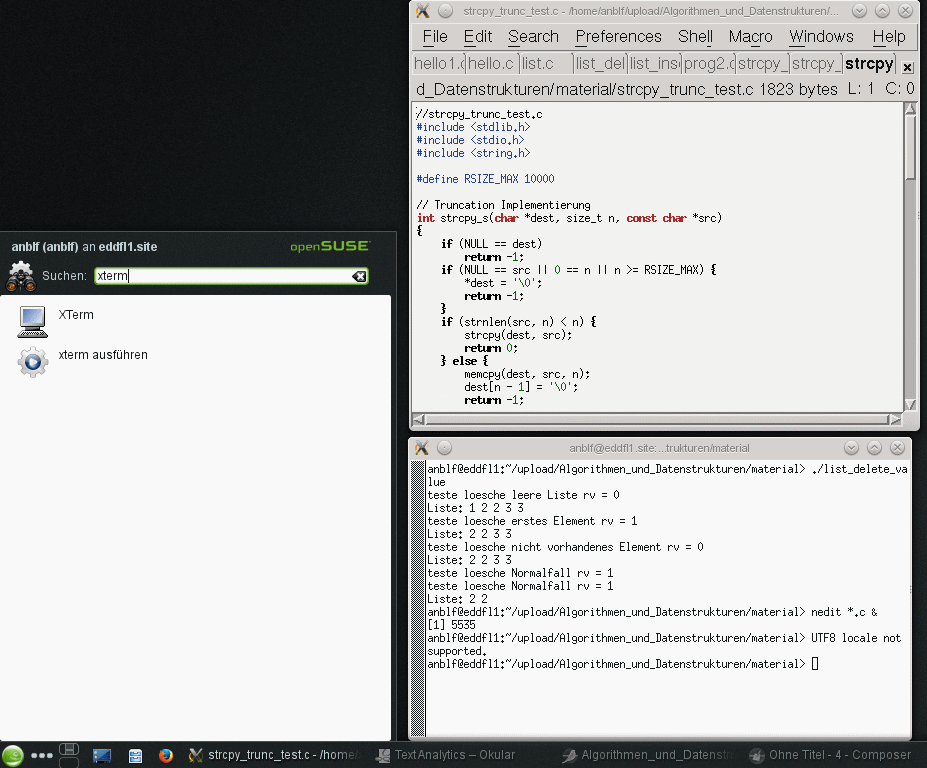
wie xterm. Im folgenden Bild wird gezeigt wie man über die
Suche-Funktion der KDE-Oberfläche das Programm xterm findet. Nach dem
Anklicken des XTerm Icon startet das xterm Fenster. Rechts unten wird das
xterm-Fenster dargestellt und rechts oben ist ein nedit Editor
Fenster zu sehen. Auf dem Computer läuft übrigens Opensuse 13.1 in der
32-bit Version. Ich setze Suse-Linux seit 1994 ein. Natürlich sind Ubuntu,
Red-Hat (Fedora) usw. auch schöne Linux Versionen.
Abbildung: KDE Benutzeroberfläche mit nedit und xterm.
Das erste Programm im Buch "Programmieren in C" von Kernighan und Ritchie
ist das inzwischen berühmte hello.c Programm. Hier das Original aus der
zweiten, "ANSI-C" Ausgabe des Buches:
#include <stdio.h>
main()
{
printf("hello, world\n");
}
// hello1.c
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("hello, world\n");
return 0;
}
Den hello1.c Quelltext wollen wir nun besprechen. Die erste Zeile beginnt
mit // dem Symbol für Kommentar bis Zeilenende. Die zweite beginnt mit einem
Doppelkreuz (#). Eine solche Zeile gehört zum Präprozessor (pre processor).
Der Präprozessor ist eine eigene Programmiersprache und ist kein C. Das
Präprozessor-Kommando #include kopiert den Inhalt der Datei stdio.h in die
Datei hello1.c, wenigstens aus Sicht des Compilers. Die Datei stdio.h
erklärt dem Compiler wichtige Details wie z.B. den Funktionsprototypen der
Funktion printf(). Die Header-Datei stdio.h wird fast immer benötigt. Wir
können sie an den Anfang jeder C-Quelltextdatei schreiben - bis wir es
besser wissen. Die Zeile int main(int argc, char *argv[]) ist ein
ähnlicher Klassiker. Liebe Studenten, bitte lernt diese Zeile auswendig.
Also "int Leerzeichen main runde-Klammer-auf int Leerzeichen argc Komma
Leerzeichen char Leerzeichen Stern argv eckige-Klammer-auf eckige-Klammer-zu
runde-Klammer-zu".
Was bedeutet nun diese Zeile? Zwischen dem C-Programm und der Kommandozeile
gibt es eine Schnittstelle. Wenn in der Kommandozeile das Programm hello1
gestartet wird, dann wird im Programm die main() Funktion aufgerufen. Die
Schnittstelle beschreibt nun was von der Kommandozeile an das Programm beim
Programm-Start übergeben wird und was vom Programm beim Programm-Ende an die
Kommandozeile zurück übergeben wird. Der erste Eingabe-Parameter (von der
Kommandozeile an das Programm) ist argc. Diese Ganzzahl-Variable
ist der argument count, d.h. benennt die Anzahl der Argumente welche
übergeben werden. Der zweite Eingabe-Parameter ist argv, der
argument vector. Diese C-String Feldvariable enthält die Argumente. Der
Ausgabe-Parameter wird durch das int am Zeilenanfang angeben. Das
Programm liefert an die Kommandozeile eine Ganzzahl zurück.
Die geschweiften Klammern { und } umschließen die Definition der Funktion.
Der Compiler muss wissen wo die Funktion anfängt und wo die Funktion endet.
In der Funktion gibt es zwei Anweisungen (statements). Die
Bibliotheksfunktion printf() erzeugt eine Ausgabe. Als Argument erhält die
Funktion die C-String Konstante "hello, world\n". In der
C-String Konstante hat das Zeichen \ eine besondere Funktion. Mit \ wird ein
Escape-Zeichen begonnen. Das Escape-Zeichen \n ist ein Zeilenvorschub. Die
zweite Anweisung return bestimmt den Rückgabewert (return value) der
Funktion main(). Traditionell bedeutet der Wert 0 das keine Fehler
aufgetreten sind im Programmlauf.
Dieser Abschnitt ist nicht nötig um C zu lernen. Deshalb steht der
Text in Kursivschrift. Vielleicht stellt sich der eine oder andere Student
die Frage: Warum muss ich C lernen? Diese Programmiersprache ist doch total
veraltet (es gibt sie seit 1973). Die Programmiersprache C ist eine
gelungene Mischung aus minimalem Sprachumfang und mächtigen Bibliotheken. C
ist für große Projekte geeignet. Das Betriebssystem Linux ist in C
geschrieben und das Betriebssystem MS-Windows höchstwahrscheinlich auch. Als
C entwickelt wurde gab es die Programmiersprachen Algol 68, PL/I und Pascal.
Diese Dinosaurier sind schon lange ausgestorben, aber C hat überlebt. Als C
schon bekannt und prominent war hat sich das US-amerikanische
Verteidigungs-Ministerium eine eigene Programmiersprache namens Ada
ausgedacht. Auch Ada hat keine Bedeutung mehr. Liebe Studenten, C ist ein
echter Überlebenskünstler. Und damit ihr echte Überlebenskünstler werdet ist
es sehr sinnvoll die Programmiersprache C als erste Programmiersprache zu
lernen. Nach C könnt und müsst ihr noch etliche weitere Programmiersprachen
lernen!
In den kursiv gesetzten Einschüben steckt hoffentlich lesenswerter Stoff.
Als Autor kann ich mir vorstellen das einige Leser nur die kursiven Absätze
lesen. Die Leser welche beides lesen finden hoffentlich den Wechsel der
Perspektive anregend welcher das Thema "Algorithmen und Datenstrukturen" in
den größeren Rahmen der praktischen Informatik stellt.
Das erste Programm hatte nur eine Funktion, im zweiten Programm gibt es zwei Funktionen. Damit die Sache nicht langweilig wird wollen wir gleichzeitig die Parameterübergabe von der Kommandozeile an das Programm und die Programmschleife kennen lernen. Ladies and Gentlemen, bitte schnallen Sie sich an! Hier kommt das Programm-Listing von prog2.c:
// prog2.c
#include <stdio.h>
#include <stdlib.h>
void ausgabe(int n)
{
int i;
for (i = 0; i < n; ++i) {
printf("Schleifendurchlauf %d\n",
i);
}
}
int main(int argc, char *argv[])
{
if (argc < 2) {
printf("usage: %s n\n",
argv[0]);
return 1;
}
int n = atoi(argv[1]);
ausgabe(n);
return 0;
}
Der kluge Leser erkennt bestimmt die Quelltext-Zeilen welche aus dem
hello1.c Listing geklaut wurden: Die erste #include Zeile, unser "int
Leerzeichen main runde-Klammer-auf" Gedicht und das return 0 am Ende des
Listing. Zuerst wollen wir die main() Funktion besprechen. In der main()
Funktion benutzen wird die Variablen argc und argv. Wie oben schon gesagt
enthält argc die Anzahl der Programmaufruf-Argumente. Das Programm wird
aufgerufen als ./prog2 3. Die Anzahl der Parameter (Parameter und
Argument bedeuten das gleiche) ist 2. Der erste Parameter ist
./prog2, der zweite Parameter ist 3. Wird das Programm mit
weniger als 2 Argumenten aufgerufen, dann wird eine kleine
Bedienungsanleitung ausgeben. Wie funktioniert dies im Detail? Die main()
Funktion beginnt mit einem if. Ein if ist eine Entscheidung, eine
Wege-Gabelung im Programm.
Unter Informatikern gibt es folgenden blöden Witz: Sagt der eine Progger
zum anderen: Der Programmfehler liegt bestimmt an einem if. Sagt der andere:
Ja, aber an welchem, ich habe davon in meinem Programm so
10000.
Unser if ist ein einfaches if, eine "entweder ich tue etwas oder ich tue
nichts" Entscheidung. Der Auslöser für den "ich tue etwas" Fall ist der
Vergleich argc < 2. Wenn argc kleiner als 2 ist, dann tue etwas.
Was getan wird steht zwischen den geschweiften Klammern { und }. Zuerst
erfolgt eine Ausgabe durch die printf() Funktion und dann wird das Programm
beendet mit dem return value 1, d.h. Fehlerfall Nummer 1 ist aufgetreten.
Das Argument der printf() Funktion soll genauer betrachtet werden. Das
Escape-Zeichen \n ist schon bekannt. Die Zeichen %s haben eine weitere
spezielle Funktion. In der Ausgabe steht nicht %s, sondern der Inhalt der
Variable argv[0]. Das Zeichen %s bedeutet: füge in der printf() Ausgabe eine
C-String Variable ein. Die C-String Variable argv[0] enthält das erste
Argument des Programmaufrufs, den Text "./prog2". Im Fehlerfall, d.h. wenn
argc den Wert 1 hat, liefert das Programm die Ausgabe usage: ./prog2
n. Jeder Leser kann natürlich gerne eine schönere Meldung
schreiben.
Was passiert aber wenn die Bedingung für das if nicht erfüllt wird, d.h. die
Entscheidung lautet "ich tue nichts"? Dann werden die Befehle in der
geschweiften Klammern nach dem if nicht ausgeführt. Der Programmfluss geht
nach der geschweiften-Klammer-zu weiter. Die Zeile int n =
atoi(argv[1]); ist unsere erste Definition einer lokalen Variable,
unsere erste Zuweisung und gleichzeitig eine Initialisierung (Vorbelegung).
Das Zeichen = hat in der Programmiersprache C nicht die Bedeutung aus der
Mathematik "links und rechts vom = Zeichen steht das gleiche" sondern hat
die Bedeutung: Kopiere das was auf der rechten Seite steht nach links. Weil
die linke Seite und die rechte Seite unterschiedliche Bedeutung haben (es
wird immer von rechts nach links kopiert) gibt es auch eigene Namen dafür.
Der Informatiker spricht von l-value und von r-value um die linke Seite von
= und die rechte Seite von = zu benennen. An der linke Seite, dem l-value,
darf nur eine Variable stehen. Auf der rechten Seite darf natürlich auch
eine Variable stehen, es darf aber auch eine Konstante stehen oder wie bei
uns eine Funktion.
Die Programmiersprache C kennt lokale Variablen, globale Variablen und heap
Variablen. Heutzutage ist die typische Variable lokal zu einer Funktion,
entweder als Teil der Funktions-Schnittstelle oder als Teil des
Funktions-Rumpf zwischen { und }. Die globalen Variablen dienen dem
Datenaustausch zwischen "entfernten" Teilen eines Programmes. Eine bekannte
globale Variable ist errno. Über diese Variable liefert das
Betriebssystem Information warum der letzte OS-call (Betriebssystemaufruf)
fehlgeschlagen ist. Die heap Variablen werden durch malloc() erzeugt und
sind dynamische Variablen, d.h. bei Programmstart ist noch nicht bekannt
wieviel Speicherplatz der heap einmal belegen wird.
Der Funktionsname atoi steht für ASCII-to-Integer und wandelt eine
Ziffernfolge in eine Ganzzahl um. Das Argument von atoi ist
argv[1], der zweite Übergabeparameter von der Kommandozeile an das
Programm. Der Rückgabe-Wert (return value) der Funktion atoi wird in die
Variable n kopiert. Die Variable n enthält in dieser Zeile nicht nur ihren
Wert sondern wird gleichzeitig definiert. Diese Kombination von Variable
erzeugen (definieren) und Variable mit einem Wert versehen ist sehr
praktisch und erst seit wenigen Jahren in der Programmiersprache C
erlaubt.
Wie bekannt können Computer eigentlich nur mit Zahlen rechnen. Deshalb ist
jedes Zeichen wie A oder 7 oder ! eine kleine Zahl im Computer. Der ASCII
Zeichensatz legt seit ungefähr 1963 fest welche kleine Zahl für das Zeichen
A usw. steht. Für Details siehe man 7 ascii. Der
ASCII-Zeichensatz kennt 128 verschiedene Zeichen. Heutzutage versucht man
alle Schriftzeichen im Computer darzustellen. Dazu benötigt man zehntausende
von unterschiedlichen Zeichen. Ein moderner und weit verbreiteter
Zeichensatz für alle Zeichen ist UTF-8. UTF-8 ist zu ASCII kompatibel, d.h.
die ersten 128 UTF-8 Zeichen sind die ASCII Zeichen. Die Programmiersprache
C versteht UTF-8 nicht besonders gut. C kommt mit dem Zeichensatz
ISO-8859-15 besser klar. In diesem Zeichensatz sind die deutschen Umlaute
und das Eurozeichen € enthalten.
Die Ziffernfolge 10 wird in einer 16-bit Ganzzahl als 0000000000001010
dargestellt. Die binäre Stelle rechts hat den Wert von 2 hoch 0 = 1. Die
nächste Stelle hat den Wert 2 hoch 1 = 2. Die weiteren Werte sind 4, 8, 16.
Wenn wir die Binärzahl 1010 mit der Stellenwertigkeit betrachten erhalten
wir 1*8+0*4+1*2+0*1 = 10.
Die zweite Funktion ausgabe() wird in der Zeile ausgabe(n);
aufgerufen. Das Programm springt bei einem Funktionsaufruf von der aktuellen
Stelle im Programm zu der Funktion, aber vorher merkt sich das Programm die
Stelle von der der Sprung aus erfolgte. Als Analogie: In einem Buch lesen
wir einen Verweis "siehe Seite 15". Damit wir nach dem Verweis ohne Probleme
weiter lesen können legen wir uns einen Zettel an der aktuellen Seite ins
Buch, springen dann auf Seite 15, lesen den Verweis und gehen dann wieder
zurück zu unserem Zettel. Diese "Zettelwirtschaft" heißt bei einem Computer
Kellerspeicher (stack). Werden mehrere Zettel benötigt (der Verweis von
Seite 15 verweist wiederum auf Seite 8) wird ein Kellerspeicherzeiger (stack
pointer) benötigt. Der lesende Finger heißt beim Computer übrigens
Programmzähler (program counter). Wenn wir über stack pointer und program
counter reden, reden wir über die Schnittstelle zwischen Computer Hardware
und Computer Software. Der program counter ist Teil der Computer Hardware,
der Inhalt des program counter ist schon Software und zeigt "wo befindet
sich das Programm gerade in der Ausführung".
Die Abkürzung von program counter ist PC. Dieses PC sollte nicht mit
"personal computer" verwechselt werden. Obwohl, ein personal computer hat
auch einen program counter.
Die Funktion ausgabe() enthält eine Zählschleife. Für C ist es typisch das
für N Durchläufe die Zählvariable (index) von 0 bis N-1 läuft. Ein Array der
Größe N hat als kleinsten Index 0 und als grössten Index N-1. Wer will kann
die Zählschleife in prog2.c auch als for (i = 1; i <= n; ++i)
schreiben. Auch bei der For-Schleife kann die Definition der Variablen i
zusammen mit der Initialisierung erfolgen als for (int i = 0; i < n;
++i). Diese Schreibweise ist erst ab C99 erlaubt, dem C Standard von
1999. Es gibt leider einen deutlichen Nachteil. Oft wird der Wert der
Zählvariable nach der Zählschleife benötigt, besonders wenn die Schleife mit
break verlassen wurde. Bei der for (int i = 0 Schreibweise
ist aber i außerhalb der Schleife nicht definiert.
Die Array-Schreibweise unter C ist z.B. dest[n - 1]. Die Zeigerschreibweise ist z.B. dest + destlen. Der C Neuling ist bei gemischter Array- und Zeigerschreibweise oft irritiert. Natürlich lässt sich ein Mini-Programm entweder nur in Array-Schreibweise oder nur in Zeiger-Schreibweise erstellen. In C Listings der 100000 Quelltextzeilen Größenordung dürften aber immer beide Schreibweisen auftreten. Die Verbindung zwischen beiden Schreibweisen ist recht einfach:
variable[index] = *(variable + index)
&variable[index] = variable + index
Eine einfache Datenstruktur ist der Stack oder LIFO (Last In First Out).
Die Teller im Geschirrschrank bilden einen Stack. Der letzte Teller welcher
auf den Tellerstapel gelegt wird wird als erster Teller wieder vom
Tellerstapel genommen. Wenn kein Teller im Tellerstapel ist, dann ist der
Stack leer (empty). Wenn der Geschirrschrank mit dem Tellerstapel voll ist,
dann ist der Stack voll (full). In der Informatik wird gerne mit der
Illusion des "unendlichen" Speicher gearbeitet. In der Realität ist jeder
Speicher endlich. Im folgenden wird der Stack mit einem Array realisiert.
Ein Array hat in der Programmiersprache C eine feste, endliche Größe.
Wie oben beschrieben wird im Computer ein Stack benutzt um die
Rücksprung-Adressen von Funktionen zu speichern. Der return stack und der
stack pointer arbeiten auf der untersten Software-Ebene des Computers. Ein
C-Programm speichert auf dem return stack auch die lokalen Variablen.
Die ersten Computer der 1950er Jahre hatten keinen return stack. Diese
Hardware-Limitierung war der Grund warum die Rekursion bei frühen FORTRAN
Versionen nicht erlaubt war. Die Programmiersprache FORTRAN kannte schon den
Unterprogramm-Aufruf. Für die Rücksprung-Adresse des Aufrufers wurde in dem
Maschinensprache-Programm des Unterprogramms eine Speicherstelle reserviert.
FORTRAN hat diesen Stack der Tiefe 1 selbst verwaltet. Weil der Hardware
stack pointer gefehlt hat, gab es natürlich auch keine lokalen Variablen in
frühen FORTRAN Versionen. "Moderne" Programmiersprachen wie C sind erst
durch moderne Computer-Hardware möglich geworden.
Der Quelltext lifo.c beginnt mit der schon bekannten #include Anweisung. Mit
der #define Anweisung wird der Präprozessor-Konstanten MAXBUF der Wert 3
zugewiesen. Unser Stack kann drei Werte speichern. Die Stack Datenstruktur
wird als struct lifo definiert. Die struct Variable ndx enthält
Verwaltungsdaten, die Feldvariable buf enthält die eigentlichen Daten, die
Nutzdaten. Mit ndx wird die Stelle in der Feldvariablen buf markiert wo der
nächste "Teller" abgelegt wird. Die Variable ndx ist der Stack-Index. Es
gibt in derProgrammiersprache C eine Verwandtschaft zwischen Array-Index und
Zeiger, siehe oben. Eine typedef Anweisung
erlaubt einem Datentype einen anderen Namen zu geben. Es wird ein Alias
definiert, d.h. über beide Namen wird das gleiche Daten-Objekt angesprochen.
Der echte Namen ist struct lifo und der Alias ist
LIFO.
Nachdem die Datenstruktur definiert wurde, können die Algorithmen für diese
Datenstruktur definiert werden. Mit der Funktion lifo_put() wird ein Datum
auf den Stack gelegt, mit der Funktion lifo_get() wird ein Datum vom Stack
geholt. Die Schnittstelle der Funktion lifo_put() besteht aus dem
Ein-/Ausgabeparametern f, dem Eingabeparameter value_ und dem Rückgabewert
der Funktion als Ausgabeparameter. Die Stack-Datenstruktur wird durch die
Funktion lifo_put geändert. Deshalb genügt es nicht wenn f nur ein
Eingabeparameter ist. In C wird durch das Einfügen von einem zusätzlichen
Stern (*) aus einem Eingabeparameter ein Ein-Ausgabeparameter. Der Parameter
f ist durch den vorangestellten Stern eine Zeigervariable geworden. Um nun
auf die einzelnen Werte der Stack-Datenstruktur zugreifen zu können ist der
-> Zugriffsoperator nötig. Der Vergleich f->ndx >= MAXBUF
bedeutet: Hole den ndx Wert von der Stack-Datenstruktur f und prüfe ob
dieser Wert größer-gleich der Konstanten MAXBUF ist. Wenn ja dann führt das
if die return -1 Anweisung aus. Der Rückgabewert -1 bedeutet es ist der
Fehler "Stack ist voll" aufgetreten. Im Normalfall, d.h. wenn der Stack noch
nicht voll ist, wird eine einzige Anweisung ausgeführt. In dieser einen
Anweisung werden die Nutzdaten und die Verwaltungsdaten geändert. Unter der
Array-Index Position f->ndx wird der Wert value_ abgelegt. Durch das an
f->ndx angehängte ++ wird nach dieser Nutzdaten-Zuweisung das
Verwaltungsdatum f->ndx um eins erhöht.
Die Programmiersprache C wird manchmal "Superassembler" genannt. Ein
Assembler ist die primitivste Programmiersprache. Wenn ein Programm
ausgeführt wird liest die CPU (central processing unit) Binärdaten ein und
interpretiert diese. Das eine Binärdatum führt zu einer Addition von zwei
Ganzzahlen, das nächste Binärdatum speichert das Additionsergebnis in einer
bestimmten Speicherstelle. Diese Binärdaten oder Maschinensprachebefehle
sind einzeln für sich betrachtet sehr primitiv. Die heutigen Computer können
aber Millionen oder gar Milliarden von diesen primitiven Befehlen pro
Sekunde ausführen und entwickeln dadurch eine große Rechenleistung. Ein
Assembler-Quelltext zeigt nun diese Maschinensprachebefehle in einer für
Menschen besser geeigneten Schreibweise nicht als Binärzahlen sondern als
Mnemonics, einprägsame Abkürzungen. So steht z.B. ADD für Addition und STO
für Abspeichern. Ein Maschinensprachebefehl der PDP-11 war "erhöhe den
Inhalt einer Speicherstelle um 1". Dieser Befehl führte zu den C Operatoren
++ und --. Neben C und seinen Verwandten C++, C# und Java haben nur wenige
Programmiersprachen so eine direkte Verbindung zwischen der
Maschinensprache-Ebene und der Hochsprachen-Ebene.
Die genaue
Auswirkung des C Operators ++ hängt davon ob ++ vor oder hinter dem
Variablenname steht. Steht ++ vor der Variable dann wird zuerst erhöht und
dann erst der Wert der Variablen benutzt für eine Zuweisung. Dieses
Verhalten heisst Pre-Inkrement. Steht ++ nach der Variablen, dann wird in
der Zuweisung der bisherige Wert der Variablen benutzt und erst dann erhöht,
ein Post-Inkrement. Die Funktion lifo_put() liefert im Normalfall den
Rückgabewert 0 für "keine Fehler".
Die Funktion lifo_get() kennt auch eine Fehlersituation. Wenn der Stack leer
ist, dann kann lifo_get() kein Datum liefern. Wie bei lifo_put() wird Erfolg
oder Misserfolg der Funktion über den Rückgabewert mitgeteilt. Der
Rückgabewert steht deshalb nicht für den Stack-value zur Verfügung. Wieder
ist die typische C Lösung die Verwendung eines zusätzlichen * in der
Funktions-Schnittstelle um aus einem Eingabeparameter einen
Ein-/Ausgabeparameter zu machen. Der Quelltext von lifo_get() ist sehr
ähnlich zum Quelltext von lifo_put(). Es wird diesmal nicht nach "Stack ist
voll" sondern nach "Stack ist leer" geprüft. Anstelle des Post-Inkrement
Operator f->ndx++ wird der Pre-Dekrement Operator --f->ndx
benutzt.
Eine Stack-Implementierung mit einer Array-Variablen kann die Kombination
Post-Inkrement und Pre-Dekrement benutzen. Die andere funktionsfähige
Kombination ist Pre-Inkrement und Post-Dekrement. Da bei uns der leere Stack
den Array-Index 0 hat, ist Post-Inkrement und Pre-Dekrement die sinnvolle
Kombination.
Der stack pointer der CPU steht bei Programmstart üblicherweise auf der
höchsten Speicheradresse und wächst "nach unten". Deshalb ist für den CPU
stack die Kombination Pre-Dekrement für das Ablegen von Rücksprungadresse
auf den Stack beim Funktions-Aufruf und Post-Inkrement für das Holen der
Rücksprungsadresse bei Funktion return sinnvoll. Der heap wächst übrigens
von unten nach oben. Im heap werden die durch malloc() angelegten
Datenstrukturen abgelegt. Weil der eine Speicherbereich von oben nach unten
wächst und der andere Speicherbereich von unten nach oben wächst ist die
größtmögliche Flexibilität gegeben. Eine richtig clevere Idee der
Informatiker der 1960er Jahre!
// lifo.c
#include <stdio.h>
#define MAXBUF 3
struct lifo {
int ndx;
int buf[MAXBUF];
};
typedef struct lifo LIFO;
int lifo_put(LIFO * f, int value_)
{
// Sonderfall: LIFO ist voll
if (f->ndx >= MAXBUF)
return -1;
// Normalfall
f->buf[f->ndx++] = value_;
return 0;
}
int lifo_get(LIFO * f, int *value_)
{
// Sonderfall: LIFO ist leer
if (0 == f->ndx) {
*value_ = 0;
return -1;
}
// Normalfall
*value_ = f->buf[--f->ndx];
return 0;
}
int main(int argc, char *argv[])
{
LIFO mylifo = { 0 };
int i;
for (i = 1; i <= MAXBUF + 1; ++i) {
int rv = lifo_put(&mylifo,
i);
printf("lifo_put %d rv = %d\n",
i, rv);
}
for (i = 1; i <= MAXBUF + 1; ++i) {
int value;
int rv = lifo_get(&mylifo,
&value);
printf("lifo_get value = %d rv =
%d\n", value, rv);
}
return 0;
}
Die main() Funktion liefert das Testbett (test bed) für unsere
Stack-Implementierung. Zuerst wird die LIFO variable mylifo definiert und
initialisiert. In der geschweiften Klammer steht nur die Konstante 0. Dieser
eine Wert wird in die erste Variable der Datenstruktur LIFO kopiert. Weil
sich die Programmiersprache C so verhält ist es immer sinnvoll die Variablen
der Datenstruktur welche Initialisierung benötigen an den Anfang zu
setzen.
Die Programmiersprache C ist und bleibt eine kleine Sprache. Vielleicht
weil C eine kleine Sprache ist, gibt es einige Verhaltensweisen welche nicht
prominent verkündet werden. Das Verhalten bei der Initialisierung wenn nur
ein Teil der Datenstruktur vorbelegt wird ist so ein "lesser known
fact".
Um die Sonderfälle zu prüfen wird die for Schleife einmal häufiger
durchlaufen als es Speicherstellen im Stack gibt. In der ersten Testschleife
wird der lifo_put() Funktion mit &mylifo die Adresse der mylifo
Datenstruktur mitgeteilt. Wenn in der Funktionsschnittstelle ein
Ein-/Ausgabeparameter benötigt wird, d.h. ein *, dann ist beim Aufruf der
Funktion oft ein & nötig. Der Operator & liefert zu einer
Datenstruktur die Adresse und der Operator * liefert von einer Adresse den
Inhalt. In der zweiten Testschleife muss zuerst eine Variable value
definiert werden bevor dann beim Aufruf der lifo_get() Funktion die Adresse
dieser Variable mit &value benutzt werden kann.
Die Beschreibung eines Programmes ist erst dann vollständig wenn nicht nur
das test bed definiert wird sondern auch die Ausgaben des test bed
dokumentiert werden. Die Ausgabe von ./lifo ist:
lifo_put 1 rv = 0
lifo_put 2 rv = 0
lifo_put 3 rv = 0
lifo_put 4 rv = -1
lifo_get value = 3 rv = 0
lifo_get value = 2 rv = 0
lifo_get value = 1 rv = 0
lifo_get value = 0 rv = -1
In der Praxis gibt es etliche Programme welche durch ein schlecht
geschriebenes Pflichtenheft und durch einen umfangreichen Testkatalog
definiert sind. Das Pflichtenheft ist üblicherweise vor der Programmierung
entstanden und der Testkatalog ist während der Programmierung entstanden.
Der Testkatalog beschreibt einzelne Testfälle mit pre-condition, event,
post-condition (Zustand vor dem Testfall, Ereignis des Testfalls und Zustand
nach dem Testfall). Die Anzahl der Testfälle geht üblicherweise in die
Tausende oder Zehntausende bei Programmen mit heute üblichem Umfang von
einigen Zehntausend Quelltextzeilen bis einige Millionen Quelltextzeilen.
Ein Pi-mal-Daumen Wert ist ein Testfall auf 10 Quelltextzeilen. Wer
heutzutage nicht zusammen mit dem Auftraggeber gemeinsam den umfangreichen
Testkatalog erstellt darf sich über eine Gerichtsverhandlung nicht wundern.
In der Prosa eines Pflichtenheftes lassen sich die unterschiedlichen
Sichtweisen und Vorstellungen von Auftragnehmer und Auftraggeber noch gut
verschleiert. Beim Testkatalog müssen beide Parteien schon deutlich
ähnlichere Vorstellungen von "was soll das Programm machen" haben. Und nur
diese durch die gemeinsame Arbeit am Testkatalog entstandene gemeinsame
Sichtweise führt zu einem erfolgreichen EDV-Projektabschluß. Wer nicht genau
weiss wo er hin will darf sich nicht wundern wenn er nicht
ankommt.
Was können Informatiker von Holzfällern lernen? Den Nutzen einer Queue.
Die Holzfäller hacken den ganzen Tag und fällen einige Bäume. Einmal am Tag
kommt ein Transporter und bringt die gefällten Bäume weg. Das Zwischenlager
für die Bäume ist die Queue oder Warteschlange oder FIFO (First in, First
out). Der erste Baum der gefällt wurde wird auch als erster Baum auf den
Transporter geladen. Dieses Detail ist für Baum-Hacker nicht wichtig aber
für Computer-Hacker. Die Holzfäller/Transporter Situation wird allgemein
Erzeuger/Verbraucher Situation genannt. Am besten funktioniert
Erzeuger/Verbraucher wenn im Durchschnitt Erzeuger und Verbraucher gleich
schnell arbeiten aber es doch immer wieder Unterschiede in der
Arbeitsgeschwindigkeit gibt. Wenn der Erzeuger etwas schneller als der
Verbraucher arbeitet, dann füllt sich die Queue auf. Wenn der Erzeuger
langsamer als der Verbraucher arbeitet, dann wird die Queue abgebaut. Wenn
die Queue ganz leer ist, dann wird der Verbraucher pausiert. Die Verwaltung
von Prozess-Zuständen (pending, running, waiting) ist hier nicht Thema und
wird spätestens in der Betriebssystem-Vorlesung behandelt.
Die Queue Datenspeicherung im folgenden Programm erfolgt mit einem Array.
Die Datenkapselung der Queue Implementierung erfolgt mit einer struct. Der
Datensatz struct fifo enthält drei Zustandsvariablen neben dem
eigentlichen Datenspeicher. Die Größe des Datenspeicher wird durch die
Präprozessor Konstante MAXBUF festgelegt. Die Variable in wird beim
Ereignis "Datum wird in der Queue abgelegt" geändert. Die Variable
out wird beim Ereignis "Datum wird aus der Queue entnommen"
geändert. Die Variable cnt enthält die Anzahl der Datenwerte in der
Queue.
// fifo.c
#include <stdio.h>
#define MAXBUF 3
struct fifo {
int in, out, cnt;
int buf[MAXBUF];
};
typedef struct fifo FIFO;
int fifo_put(FIFO * f, int value_)
{
// Sonderfall: FIFO ist voll
if (f->cnt >= MAXBUF)
return -1;
// Normalfall
f->buf[f->in++] = value_;
f->in %= MAXBUF;
++f->cnt;
return 0;
}
int fifo_get(FIFO * f, int *value_)
{
// Sonderfall: FIFO ist leer
if (0 == f->cnt) {
*value_ = 0;
return -1;
}
// Normalfall
*value_ = f->buf[f->out++];
f->out %= MAXBUF;
--f->cnt;
return 0;
}
int main(int argc, char *argv[])
{
FIFO myfifo = { 0, 0, 0 };
int i;
for (i = 1; i <= MAXBUF + 1; ++i) {
int rv = fifo_put(&myfifo,
i);
printf("fifo_put %d rv = %d\n",
i, rv);
}
for (i = 1; i <= MAXBUF + 1; ++i) {
int value;
int rv = fifo_get(&myfifo,
&value);
printf("fifo_get value = %d rv =
%d\n", value, rv);
}
return 0;
}
Die Ausgabe von ./fifo ist:
fifo_put 1 rv = 0
fifo_put 2 rv = 0
fifo_put 3 rv = 0
fifo_put 4 rv = -1
fifo_get value = 1 rv = 0
fifo_get value = 2 rv = 0
fifo_get value = 3 rv = 0
fifo_get value = 0 rv = -1
Die Zeichenkettenverarbeitung unter C hat zu Recht einen schlechten Ruf. Die string Klasse von C++ funktioniert viel besser. Es gibt aber noch sehr viel C Quelltext auf der Welt. Deshalb soll hier der sichere Umgang mit C-Strings vorgestellt werden. Zuerst wird aber der C-String vorgestellt.
Ein C-String ist ein char Array, eine Feldvariable mit dem Type char.
Wird in der Programmiersprache C ein Array an eine Funktion übergeben als
Parameter, dann erfolgt Call-by-Reference. Es wird nicht eine Kopie des
C-Strings übergeben, sondern ein Zeiger auf den C-String. Ein Zeiger
(pointer) ist die Speicheradresse, d.h. die Stelle im Computer wo der
C-String abgelegt ist. Wird in der Funktion der übergebene C-String
geändert, dann ist diese Änderung dauerhaft. Auch nachdem die Funktion
verlassen wurde bleibt der C-String geändert. Zum Vergleich: Ein int Wert
wird als Call-by-Value übergeben. Die Funktion erhält eine Kopie des Wertes.
Ändert die Funktion ihre Kopie des int Wert ist diese Änderung nicht
dauerhaft. Warum wird nun ein C-String als Zeiger übergeben? Der C-String
ist ein Array. Unter C werden alle Arrays als Call-by-Reference übergeben.
Das Kopieren von (langen) Arrays dauert eine gewisse Zeit und benötigt auch
Speicherplatz für die Kopie. Die Call-by-Reference Parameterübergabe ist
eine Möglichkeit Zeit und Speicherplatz zu sparen.
C wurde ab 1971 entwickelt. Zu dieser Zeit war der Digital PDP-11/20 ein
typischer Computer. Dieser Computer hatte einen maximalen Arbeitsspeicher
von 28672 16-Bit Worten. C wurde für das Betriebssystem UNIX entwickelt und
die C Version von UNIX lief zuerst auf einer PDP-11. Natürlich durfte das
Betriebssystem nicht den kompletten Arbeitsspeicher "auffressen" sondern
sollte möglichst viel Speicher für die Nutzerprogramme übrig lassen.
Neben dem Call-by-Reference Problem gibt es das Größen-Problem. Wenn eine
Funktion einen C-String erhält, d.h. einen Zeiger auf ein char Array, dann
ist die Größe des char Array nicht bekannt. Die übliche Lösung in C ist, das
ein C-String mit zwei Parametern, einem Doppelparameter, beschrieben wird.
Der erste Parameter ist der Zeiger, der zweite Parameter ist die Größe des
Array. Der Operator sizeof(variable) liefert die Größe des
Array.
Das dritte Problem sind C-Strings ohne NUL-Byte am Ende. Ein C-String kann
ja kürzer als die Array-Größe sein. Damit eine Funktion wie strlen() oder
printf() die aktuelle Länge des C-Strings erkennt wird nach den gültigen
Zeichen im C-String ein Zeichen mit der Wert 0 gesetzt. Im ASCII Zeichensatz
wird dieses Steuerzeichen NUL genannt, deshalb NUL-Byte.
Das folgende Programm testet die Standard C-String Funktionen strlen(),
strcpy() und strcat(). Dabei liefert strlen() die Länge des C-Strings, d.h.
wie viele Zeichen enthält das char Array vor dem ersten NUL-Byte. Die
Funktion strcpy() kopiert den Inhalt eines C-String in einen anderen
C-String. Eine Zuweisung string1 = string2 kopiert nur den Zeiger.
Mit strcat() wird die Kopie des zweiten Strings an den ersten String
angehängt (concatenation).
In der Funktion f() wird zuerst ein C-String ohne NUL-Byte erzeugt. Dies ist
erlaubt, der Compiler meldet keine Warning oder Error. Mit printf() wird der
Wert von sizeof() und der Wert von strlen() ausgegeben. Die Funktion
strlen() versagt weil das NUL-Byte fehlt. Üblicherweise gibt es im
Arbeitsspeicher nach dem char Array Variable eine Speicherstelle welche
zufällig ein NUL-Byte enthält und für strlen() das Stringende-Zeichen
liefert. Die Funktion g() zeigt was passiert wenn ein langer C-String in ein
zu kurzes char Array kopiert wird. Die Speicherstellen hinter dem char Array
werden überschrieben. Auf meinem Computer erfolgt ein Programmabsturz mit
der Fehlermeldung "Speicherzugriffsfehler". In der dritten Funktion h()
zeigt strcat() seine Schwächen. Ähnlich wie bei g() werden Speicherstellen
überschrieben die nicht zur char Array Variable gehören. Auch hier erfolgt
ein Programmabsturz, diesmal ohne Fehlermeldung.
Der aufmerksame Leser erinnert sich vielleicht noch an das C Strickmuster:
Eine kleine Sprache mit einer großen Bibliothek. Die Funktionen strlen(),
strcpy() und strcat() sind Teil der Bibliothek und nicht Teil der
Programmiersprache. Sie können leicht durch andere Funktionen ersetzt
werden.
// strcpy_test.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void f()
{
char s[5] = { 'a', 'b', 'c', 'd', 'e' };
printf("sizeof(s) = %d\n", sizeof(s));
printf("strlen(s) = %d\n", strlen(s));
}
void g()
{
char s[10];
strcpy(s, "a very long string and more");
printf("%s\n", s);
}
void h()
{
char s[10];
strcpy(s, "a");
printf("%s\n", s);
int i;
for (i = 0; i < 20; ++i) {
strcat(s, "b");
printf("%2d: %s\n", i, s);
}
}
int main(int argc, char *argv[])
{
if (argc < 2) {
printf("usage: %s n\n",
argv[0]);
return 1;
}
int n = atoi(argv[1]);
switch (n) {
case 1:
f();
break;
case 2:
g();
break;
case 3:
h();
break;
default:
printf("n is 1 to 3\n");
return 2;
}
return 0;
}
Zum Abschluß noch ein paar Worte zur main() Funktion. Die switch()
Anweisung kann als Alternative zu if() else if() else if() else
Konstruktionen benutzt werden wenn die Bedingungen in den if() ein Vergleich
zu konstanten Zahlen sind. Jeder case Zweig wird meistens mit einem break
abgeschlossen. Dieses break ist ein Sprung hinter die geschweifte-Klammer-zu
der switch() Anweisung. Manchmal ist es sinnvoll auf ein break zu
verzichten. Dann wird oft anstelle von break ein C Kommentar /* no break
*/ geschrieben um diese Absicht deutlich zu machen.
ISO und IEC produzieren internationale Standards. In dem Dokument
TR24731-1
werden Bibliotheksfunktionen beschrieben welche robuster sind als die POSIX
Funktionen strlen(), strcpy() und strcat(). Das Größen-Problem von C-Strings
wird durch die TR24731-1 C-String Funktionen behandelt. Diese Funktionen
benutzen einen Doppelparameter (Zeiger und Größe) für den Ziel (destination)
C-String. Auch die TR24731-1 C-Strings verarbeiten C-Strings ohne NUL-Byte
fehlerhaft wenn die char Array Größe des Quell-C-String kleiner ist als die
Größe des Ziel-C-String.
In dem folgenden Listing fehlt die main() Funktion. Sie ist genauso wie im
vorherigen Listing. Die POSIX.1-2008 Funktion strnlen() ersetzt strlen().
Die TR24731-1 Funktion strcpy_s() ersetzt strcpy() und strcat_s() ersetzt
strcat(). Unter Linux sind die TR24731-1 Funktionen nicht
Standard-Lieferumfang, bei MS-Windows schon. Anhand der TR24731-1
Beschreibung dieser Funktionen sind sie aber schnell programmiert.
Die Funktion strcpy_s() ruft die Funktion strcpy() auf wenn einige Prüfungen
erfolgreich waren. Zuerst werden die Übergabeparameter geprüft. Die C-String
Variablen müssen gültige Zeiger sein, die Größe des Ziel-C-String muss
zwischen einer unteren und oberen Grenze liegen. Die untere Grenze ist
größer als 0 und die obere Grenze ist kleiner als die Präprozessor Konstante
RSIZE_MAX. Falls die Prüfungen fehlschlagen wird der Inhalt des Ziel
C-String gelöscht und ein Rückgabewert ungleich 0 geliefert. Der Operator ||
bedeutet logisches Oder. Zur Erinnerung: Ein Rückgabewert von 0 bedeutet bei
C oft "kein Fehler", aber nicht immer. Einige Leser stören sich bestimmt an
der goto Anweisung. Ein goto ist gültiges C und als Sprung zu einem
gemeinsamen "error-exit" sogar strukturiert nach meiner Meinung.
// strcpy_TR24731_test.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define RSIZE_MAX 10000
// TR24731-1 Implementierung
int strcpy_s(char *dest, size_t n, const char *src)
{
if (NULL == dest)
return -1;
if (NULL == src || 0 == n || n >= RSIZE_MAX)
goto error;
if (strnlen(src, n) < n) {
strcpy(dest, src);
return 0;
}
error:
*dest = '\0';
return -1;
}
// TR24731-1 Implementierung
int strcat_s(char *dest, size_t n, const char *src)
{
if (NULL == dest)
return -1;
if (NULL == src || 0 == n || n >= RSIZE_MAX)
goto error;
if (strnlen(dest, n) + strnlen(src, n) < n) {
strcat(dest, src);
return 0;
}
error:
*dest = '\0';
return -1;
}
void f()
{
char s[5] = { 'a', 'b', 'c', 'd', 'e' };
printf("sizeof(s) = %d\n", sizeof(s));
printf("strnlen(s) = %d\n", strnlen(s, sizeof(s)));
}
void g()
{
char s[10];
strcpy_s(s, sizeof(s), "a very long string and
more");
printf("%s\n", s);
}
void h()
{
char s[10];
strcpy_s(s, sizeof(s), "a");
printf("%s\n", s);
int i;
for (i = 0; i < 20; ++i) {
strcat_s(s, sizeof(s), "b");
printf("%2d: %s\n", i, s);
}
}
Es gibt einige Kritik an TR24731-1. Wegen dieser Kritik gibt es diese
Funktionen nicht in der glibc. Für mich enthält die Kritik viel "real
programmer" Machismo: Echte Programmierer brauchen keinen Zeiger/Größe
Doppelparameter. Echte Programmierer schießen sich lieber in den
Fuß.
Für mich ist die TR24731-1 Lösung im Fehlerfall einen leeren C-String zu
liefern nicht die beste Lösung. Bei der Truncation (Abschneiden) Methode
wird die Variable bis zur maximalen Größe gefüllt. Es wird soviel geliefert
wie in den Ziel-C-String hineinpasst. Im folgenden Listing werden nur die
Änderungen zum vorherigen Listing gezeigt. Die Funktion memcpy() kopiert
eine Anzahl von Bytes ohne Auswertung des NUL-Bytes.
// strcpy_trunc_test.c
// Truncation Implementierung
int strcpy_s(char *dest, size_t n, const char *src)
{
if (NULL == dest)
return -1;
if (NULL == src || 0 == n || n >= RSIZE_MAX) {
*dest = '\0';
return -1;
}
if (strnlen(src, n) < n) {
strcpy(dest, src);
return 0;
} else {
memcpy(dest, src, n);
dest[n - 1] = '\0';
return -1;
}
}
// Truncation Implementierung
int strcat_s(char *dest, size_t n, const char *src)
{
if (NULL == dest)
return -1;
if (NULL == src || 0 == n || n >= RSIZE_MAX) {
*dest = '\0';
return -1;
}
size_t destlen = strnlen(dest, n);
if (destlen + strnlen(src, n) < n) {
strcat(dest, src);
return 0;
} else {
memcpy(dest + destlen, src, n -
destlen);
dest[n - 1] = '\0';
return -1;
}
}
Die Liste (list) ist nach dem Array die nächste Datenstruktur welche
vorgestellt wird. Es gibt die einfach verkettete Liste, die einfach
verkettete Liste mit einen Zeiger auf das Listen-Ende (tail pointer) und die
doppelt verkettete Liste. In folgenden beschäftigen wir uns mit der einfach
verketteten Liste.
Früher war die Welt einfach: die Programmiersprache FORTRAN kannte nur
Arrays und die Programmiersprache Lisp kannte nur Listen. Heute kann jede
Programmiersprache alles und dank so leistungsfähiger Bibliotheken wie der
Standard Template Library (STL) von C++ kann jeder Programmierer diese
Leistung auch einfach nutzen. Wir arbeiten aber mit C und müssen deshalb die
Listen von Hand programmieren.
Das Array hat den Nachteil der festen Größe. Eine Liste ist eine dynamische
Datenstruktur. Es wird nur soviel Arbeitsspeicher benötigt wie es auch
Datensätze in der Liste gibt. Das Einfügen eines neuen Datums in ein
sortiertes Array benötigt viel Um-kopieren. Bei einer
sortierten Liste muss nur die Einfüge-Stelle gesucht werden, das Um-kopieren
entfällt. Natürlich gibt es die Vorteile der Liste nicht umsonst. Jedes
Element der Liste benötigt Speicherplatz für einen Zeiger auf das nächste
Element der Liste.
In einer Programmiersprache ohne Garbage Collector (automatisches
Aufräumen von nicht mehr belegtem Arbeitsspeicher) wie C und C++ muss der
Programmierer zum korrekten Zeitpunkt den nicht mehr benötigten
Arbeitsspeicher freigeben. Hier passieren oft Programmierfehler. Entweder
wird der Speicher nicht freigegeben und das Programm erstickt irgendwann an
diesem "Ballast" oder es wird zu früh der Speicher freigegeben. Oft
funktioniert das Programm dann noch eine Weile bis der fälschlich
freigegebene Speicher anders benutzt wird. Erst dann wird der alte Inhalt
geändert und erst dann wird der Programmierfehler sichtbar. Damit solche Fehlerquellen
schnell sichtbar werden ist es sinnvoll einen Speicherbereich vor dem
Freigeben mit NUL-Bytes zu überschreiben.
Die einfach verkettete Liste wird in C üblicherweise mit einem struct
realisiert. Ein struct ist ein Datensatz oder ein Record oder eine Struktur.
In einem struct gibt es mehrere Datenfelder. Minimal nötig für die Liste ist
ein Datenfeld für den Zeiger auf das nächste Listenelement und ein Datenfeld
für die Nutzdaten. Die einfachsten Nutzdaten sind Ganzzahlen. Eine einfache
Liste hat somit folgende Datendefinition:
typedef struct elem *LIST;
struct elem {
LIST next;
int value;
};
Die zwei Datenelemente des struct elem sind next und value. Vor der struct
Definition gibt es noch eine Definition eines Zeigers mit typedef. Mit
typedef wird die Tipparbeit reduziert. Für den Compiler sind die Ausdrücke
struct elem * und LIST identisch. Die beiden Anweisungen
sehen aus wie ein Henne-Ei Problem. Die erste Anweisung bezieht sich auf
elem, eine struct die noch gar nicht definiert ist. Es ist aber kein
Henne-Ei Problem. Ein Zeiger hat immer eine bestimmte Größe, egal auf was
der Zeiger zeigt.
Bei einem 32-bit Betriebssystem ist ein Zeiger 32 bit groß, bei einem
64-bit Betriebssystem ist er 64 bit groß, eigentlich logisch, oder?
Eine Ganzzahl (int) ist üblicherweise 32 bit groß. Unser struct
elem besteht bei einem 64-bit Betriebssystem somit aus 32 bit
Nutzdaten und 64 bit Verwaltungsdaten. Wer genau 4GByte Arbeitsspeicher hat
sollte ein 32-bit Betriebssystem benutzen, einfach weil da das Verhältnis
von Nutzdaten zu Verwaltungsdaten besser ist.
Die Funktion list_print() zeigt den
Inhalt der Liste. Das Liste durchlaufen benutzt eine for Schleife. Die for
Schleife von C ist sehr flexibel. Zwischen der runden-Klammer-auf und der
runden-Klammer-zu stehen drei, durch Semikolon getrennte, Ausdrücke. Der
erste Ausdrück initialisiert die for Schleifen Variable. Der zweite Ausdruck
beendet die for Schleife und der dritte Ausdruck gibt der for Schleifen
Variable einen neuen Wert. Für eine Liste ist der neue Wert der Inhalt des
next-Feldes und die Schleifen-Ende Bedingung ist das dieses Feld den Wert
NULL hat.
Einige Professoren benutzen für das Liste durchlaufen eine while Schleife
anstelle einer for Schleife. Das ist schlecht. Bei einer for Schleife ist
genau festgelegt wo der Ausdruck für Initialisierung und für die Berechnung
der neuen for Schleifen Variable steht. Bei einer while Schleife müssen
diese Ausdrücke auch vorhanden sein, aber der Quelltext-Leser muss sie erst
suchen. "Das haben wir schon immer so gemacht" ist eine schlechte Begründung
und der natürliche Feind der Verbesserung.
Die Funktion list_insert() hat einige Besonderheiten in der Schnittstelle.
An die Funktion wird LIST *l übergeben. Laut typedef ist LIST ein Zeiger auf
ein struct elem. Ein LIST *l ist somit ein Zeiger auf einen Zeiger auf eine
struct elem. Was soll das? Ein zusätzlicher Stern ist in C die übliche
Methode um aus einem Eingabeparameter einen Ein- und Ausgabeparameter zu
machen. Die Funktion list_insert verändert die Liste. Ein
Ein-Ausgabeparameter ist da praktisch. Die Alternative ist die Liste einmal
als Eingabeparameter aufzuführen und dann als Rückgabewert erneut zu haben.
Dieses umständliche Verfahren ist bei der Programmiersprache Java nötig.
Die Programmiersprachen Pascal und Java haben keine Zeiger. Deshalb kann
es in diesen Programmiersprachen keine Programmfehler durch Zeiger geben
(Applaus, Applaus). Dafür haben diese Programmiersprachen Referenzen.
Referenzen sind Zeiger für Arme. Ob Programme mit Referenzen weniger
Programmfehler haben als Programme mit Zeigern ist noch aktuelles
Forschungsgebiet. Erste Erkenntnisse lauten: "Man kann in jeder
Programmiersprache FORTRAN programmieren".
Der zweite Eingabeparameter hat mit value_ eine seltsamen Namen. Der
Hintergrund ist einfach: Die Programmiersprache C++ erlaubt für eine
Variable und für ein struct Datenelement in der gleichen Funktion nicht den
gleichen Namen. Bevor wir uns nun mühevoll einen anderen Namen für den
Eingabeparameter ausdenken, hängen wir einfach einen Unterstrich an den
Namen. Achtung: Vor den Namen sollten wir keinen Unterstrich anfügen. Die
Laufzeitumgebung des Programms benötigt einige Variablen. Diese Variablen
beginnen mit Unterstrich. Solange man es nicht genau weiß sollte man im
eigenen Programm solche Variablen nicht benutzen.
Der return value von list_insert() ist 0 für keine Fehler und -1 für Fehler.
Die Fehlerursache ist ein fehlgeschlagener Aufruf von malloc(). Die Funktion
malloc() reserviert Arbeitsspeicher beim Betriebssystem. Dieser
Arbeitsspeicher ist endlich. In der Funktion main() wird in der ersten for
Schleife der Arbeitsspeicher angefordert. Eine Liste mit 10 Elementen macht
noch keine Speichernot. Wird aber aus 10 eine Milliarde (1000000000) dann
wird es interessant. Mein Computer mit einem 32-bit Linux sagt dann:
Error: out of memory at i = 201076697. Für mich als "altgedienter"
Informatiker ist es sehr wichtig den jungen Informatikern gleich die
richtigen Lektionen zu vermitteln: error handling ist nötig! Und jedes error
handling muss getestet werden! Bei einem Programm mit einigen dutzend
Quelltextzeilen lässt sich die Fehlerursache vielleicht ohne error handling
finden, bei einem Programm mit 50000 Zeilen nicht mehr. Und 50000 LOC (lines
of code) sind heute mittelgroße Programme. Was ist nun error handling? Ganz
einfach, wir werten die Rückgabewerte aus und melden sie nach oben. Der
eigentliche Fehler "kein freier Arbeitsspeicher mehr" wird von malloc()
entdeckt. Das return -1 meldet diesen Fehler an den Aufrufer von
list_insert(). Der Aufrufer von list_insert() wertet ebenfalls den
Rückgabewert aus und schreibt eine Fehlermeldung. Für das Verständnis von
list_insert() ist dieses error handling nicht nötig, für das Verständnis von
praktischer Informatik aber schon.
Die Steigerung von error handling ist error recovery: Wie kann ein
Programm wieder aus einer Fehlersituation herauskommen. Error recovery ist
ein Thema für Fortgeschrittene. Im Moment nur soviel: Die mission critical
Software der Deutschen Flugsicherung enthält sehr viel error handling und
error recovery Quelltext. In mancher Software stellen diese Teile sogar die
Mehrheit des Quelltextes.
Die eigentliche Funktion von list_insert() ist einfach. Zuerst wird ein
neues Listenelement erzeugt und mit den Nutzdaten gefüllt. Im zweiten
Schritt werden Zeiger umsortiert. Der Zeiger vom Listenkopf zeigt nicht mehr
auf das alte erste Listenelement sondern auf das neue erste Listenelement.
Und der alte Zeiger vom Listenkopf ist nun im next-Feld des neuen ersten
Listenelements. Die Reihenfolge diese beiden Zeigermanipulationen ist
wichtig. Zuerst muss der alte Listenkopf-Zeiger kopiert werden, bevor der
neue Listenkopf-Zeiger gesetzt werden kann. Der Listenkopf ist übrigens der
Ein-Ausgabeparameter LIST *l der Funktion list_insert().
// list.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct elem *LIST;
struct elem {
LIST next;
int
value;
};
// Liste durchlaufen und ausgeben
void list_print(LIST l)
{
printf("Liste: ");
LIST j;
for (j = l; j != NULL; j = j->next) {
printf("%d ", j->value);
}
printf("\n");
}
// einfuegen am Kopf
int list_insert(LIST * l, int value_)
{
// neues Element erzeugen
LIST pelem = malloc(sizeof(struct elem));
if (NULL == pelem)
return -1;
pelem->value = value_;
// neues Element am Listen-Kopf einfuegen
pelem->next = *l;
*l = pelem;
return 0;
}
// loeschen am Kopf
int list_delete(LIST * l)
{
// Sonderfall leere Liste
if (NULL == *l)
return 0; // kein
Element geloescht
// erstes Element loeschen
LIST oldl = *l;
*l = oldi->next;
memset(oldl, 0, sizeof(struct elem));
free(oldl);
return 1; // ein Element geloescht
}
int main(int argc, char *argv[])
{
if (argc < 2) {
printf("usage: %s n\n",
argv[0]);
return 1;
}
int n = atoi(argv[1]);
// Liste definieren und initialisieren
LIST mylist = NULL;
// Liste fuellen
int i;
for (i = 0; i < n; ++i) {
int rv = list_insert(&mylist,
i);
if (rv) {
printf("Error: out of memory at i = %d\n", i);
return
1;
}
}
list_print(mylist);
// Liste loeschen
for (i = 0; i < n+1; ++i) {
int rv =
list_delete(&mylist);
if (0 == rv) {
printf("Error: List empty = %d\n", i);
return
1;
}
}
return 0;
}
Die main() Funktion enthält die übliche
Kommandozeile-Schnittstelle und beginnt mit dem if für die
Mini-Bedienungsanleitung. Die vier Tätigkeiten der main() Funktion sind
erzeugen der Liste, füllen der Liste, ausgeben der Liste und löschen der
Liste. Wie schon in den vorherigen Programmen wird Definition und
Initialisierung einer Variable in einer Anweisung ausgeführt. Dies sind
"kleine Fische", aber trotzdem wichtige "best practices".
Das Liste füllen erfolgt mit einer Zählschleife. So weit so bekannt. Die
Funktion list_print wurde oben besprochen.
Einfügen am Kopf der Liste ist einfach und entfernen am Kopf der Liste
ebenfalls. Es gibt nur den Sonderfall der leeren Liste. Beim löschen des
ersten Elements muß zuerst eine Kopie des Listenkopf-Zeigers angelegt
werden. Diese Kopie in der Variablen oldl wird für die Speicherfreigabe
free() benötigt. Vor der Freigabe wird das struct elem noch mit NUL-Bytes
vollgeschrieben mit der Anweisung memset(oldl, 0, sizeof(struct
elem));. Dies ist ein Beispiel für defensive Programmierung wie
oben empfohlen. Eigentlich ist diese
Anweisung überflüssig, aber man hat als Informatiker schon einige Fehler
gesehen. Und diese Fehler waren bei erster Betrachtung alle nicht logisch.
In der main() Funktion wird list_delete() einmal häufiger als list_insert()
aufgerufen um auch den Sonderfall löschen in der leeren Liste zu
testen.
Der value eines Listenelements kann ebenfalls der Grund zum löschen sein.
Zuerst gibt es eine grundsätzliche Design-Frage: Was soll passieren wenn es
mehrere Listen-Elemente mit dem gleichen value gibt und dieser value
gelöscht wird? Soll die list_delete() genau ein Element löschen oder alle
Elemente mit diesem value? Wenn nur ein Element gelöscht wird, wie sollte
dann die list_delete() Schnittstelle aussehen damit man auch alle Elemente
löschen kann? Weiterhin gibt es einige Sonderfälle zu berücksichtigen. Wenn
die Liste leer ist liegt der erste Sonderfall vor. Wenn das erste Element in
der Liste gelöscht werden soll liegt der zweite Sonderfall vor.
Der Informatik-Professor Niklaus Wirth, welcher 1975 das erste Buch mit
dem Titel "Algorithmen und Datenstrukturen" geschrieben hat, empfiehlt die
Methode der schrittweisen Verfeinerung. Wir schreiben zuerst eine
unvollständige Version des Programms. Diese Version kann vielleicht gerade
den einfachsten Sonderfall bearbeiten. Wir können diese Programmversion aber
schon testen. Es gibt das Sprichwort: "der Appetit kommt beim Essen". Oft
hilft die Beschäftigung mit der Programmierung und dem Test des leichtesten
Falles dem Informatiker dabei auch eine Lösung für die anderen Fälle zu
finden. Wenn jeder Fall für sich programmiert und gleich darauf getestet
wird, dann vergisst man so leicht auch nicht das Testen von allen Fällen,
man geht ja schrittweise voran. Dieses uralte Vorgehen wird heutzutage
als test driven
development (TDD) verkauft. Die Neuerung bei TDD ist: Zuerst muss
man den Test definieren mit Eingangsbedingung, Ereignis und Ergebnis
(initial condition, event, result). Erst dann beginnt die Arbeit am "system
under test".
Bei dem folgenden Listing fehlt der Anfang. Aus dem obigen Listing list.c
wird der Quelltext bis zum Ende der list_insert() Funktion benötigt. Die
list_delete_value() Funktion beginnt wie die list_delete() Funktion. Kleine
Änderungen gibt es wegen dem Parameter value_. Erst die letzte for Schleife in der Funktion ist richtig
neu. Es ist die bis jetzt komplizierteste for Schleife. Wie bekannt stehen
zwischen runde-Klammer-auf und runde-Klammer-zu drei Ausdrücke. Durch ein
Komma in solch einem Ausdruck lassen sich sogar mehrere Anweisungen
schreiben. Mit dem Ausdruck oldi = *l, i = oldi->next werden die
zwei Variablen oldi und i initialisiert und mit dem Ausdruck oldi = i, i
= i->next werden die Variablen oldi und i auf neue Werte gesetzt.
Die Variable oldi enthält den Wert von i aus dem letzten Schleifendurchlauf.
Warum benötigen wir dies? Wenn wir ein zu löschendes struct elem gefunden
haben, dann müssen wir das next-Feld des "upstream" struct elem ändern. Dies
ist nur möglich wenn wir uns den vorherigen Wert von i aufgehoben haben.
Beim Durchlaufen der Liste gibt es nur eine "Fahrtrichtung". Die Richtung
aus der wir kommen ist flussaufwärts (upstream), die Richtung in die wir
laufen ist flussabwärts (downstream).
Einige Programmierer sagen: "C sieht aus als wenn sich ein Gürteltier auf
der Tastatur gewälzt hat". Dieser Aussage will ich nicht widersprechen.
Trotzdem gehört die Schreibweise mit der Manipulation von zwei Variablen zum
normalen Gebrauch von C. Auch wenn hier nur einfache Algorithmen und
Datenstrukturen vorgestellt werden möchte ich trotzdem kein Kindergarten C
zeigen.
// list_delete_value.c
// ein Element mit value loeschen
int list_delete_value(LIST * l, int value_)
{
// Sonderfall leere Liste
if (NULL == *l)
return 0; // kein
Element geloescht
// Sonderfall erstes Element
if ((*l)->value == value_) {
LIST oldl = *l;
*l = (*l)->next;
memset(oldl, 0, sizeof(struct
elem));
free(oldl);
return 1; // ein
Element geloescht
}
// Normalfall weitere Elemente
LIST i, oldi;
for (oldi = *l, i = oldi->next; i != NULL; oldi = i, i
= i->next) {
if (i->value == value_) {
oldi->next = i->next;
memset(i,
0, sizeof(struct elem));
free(i);
return
1;
}
}
return 0;
}
int main(int argc, char *argv[])
{
LIST mylist = NULL;
// teste loesche leere Liste
int rv = list_delete_value(&mylist, 1);
printf("teste loesche leere Liste rv = %d\n", rv);
list_insert(&mylist, 3);
list_insert(&mylist, 3);
list_insert(&mylist, 2);
list_insert(&mylist, 2);
list_insert(&mylist, 1);
list_print(mylist);
// teste loesche erstes Element
rv = list_delete_value(&mylist, 1);
printf("teste loesche erstes Element rv = %d\n", rv);
list_print(mylist);
// teste loesche nicht vorhandenes Element
rv = list_delete_value(&mylist, 4);
printf("teste loesche nicht vorhandenes Element rv =
%d\n", rv);
list_print(mylist);
// teste loeschen mehrere Elemente
while ((rv = list_delete_value(&mylist, 3))) {
printf("teste loesche Normalfall
rv = %d\n", rv);
}
list_print(mylist);
return 0;
}
Die main() Funktion realisiert unser Testbett (test bed). Was zu einem
richtigen Testbett noch fehlt sind die korrekten Antworten des Programms.
Deshalb folgt die Ausgabe von dem Programmlauf. Von mir als der höchsten
Testinstanz wird diese Ausgabe zur "baseline" erklärt. Nach
Programmänderungen wie einer Laufzeitoptimierung soll das Programm das
gleiche Verhalten zeigen wie die "baseline" Version.
Das die "baseline" Version eines Programmes das korrekte Verhalten zeigt
ist ein (Irr)-Glaube. Es gibt immer die Möglichkeit das in der "baseline"
auch ein Fehler steckt der durch eine Programmänderung repariert wurde. Bei
Abweichungen ist immer nach der echten Fehlerquelle zu suchen. Die
Fehlerquelle kann vor dem Computer sitzen (Bedien- oder Wahrnehmungsfehler
des Testers), der Fehler kann in der neuen Software-Version oder in der
alten Software-Version sitzen.
Hier kommt die "Soll"-Ausgabe des Programms:
teste loesche leere Liste rv = 0
Liste: 1 2 2 3 3
teste loesche erstes Element rv = 1
Liste: 2 2 3 3
teste loesche nicht vorhandenes Element rv = 0
Liste: 2 2 3 3
teste loesche Normalfall rv = 1
teste loesche Normalfall rv = 1
Liste: 2 2
Und nun die Klausur-relevante Frage: Wer hat alleine durch Lesen des
Quelltextes und "ausführen" des Quelltextes im Kopf herausgefunden was die
Programmausgabe ist?
In der main() Funktion haben wir zum ersten Mal eine while Schleife benutzt.
Nach meiner Meinung ist die while Schleife nur dann sinnvoll wenn weder eine
(Zähl-)Variable Initialisierung noch ein Änderung der (Zähl-)Variable bei
jedem Schleifendurchlauf nötig sind. In der while Schleife findet eine
Zuweisung statt. Dies ist eine praktische Eigenschaft von C. Der Compiler
gibt bei der Option -Wall die Warnung "suggest parentheses around
assignment". Deshalb gibt es ein Paar Klammern ( ) mehr als nötig.
Anstelle von while ((rv = list_delete_value(&mylist, 3))) kann
man auch schreiben while (0 != (rv = list_delete_value(&mylist,
3))). Bei der zweiten Schreibweise sind wegen der Vorrang-Regeln von C
die Klammern um die Zuweisung nötig.
Es gibt immer kluge Sprüche wenn ein Thema etwas kompliziert wird. Im
Zusammenhang mit der Operator-Priorität lautet der kluge Spruch: "Im Zweifel
benutzen sie Klammern". Überflüssige Klammern finde ich häßlich. Mein Tipp
lautet deshalb: "kompilieren Sie mit -Wall und hören Sie auf den Compiler".
Ein Editor welcher zu jeder Klammer-auf die passende Klammer-zu anzeigt ist
hilfreich. Der nedit kann dies.
Weiter oben wurde als Vorteil der
Liste genannt das es einfach ist eine sortierte Liste auch nach dem Einfügen
von neuen Datensätzen sortiert zu halten. Ein Array macht in dieser Hinsicht
mehr Arbeit. Vor den Erfolg haben die Götter den Schweiß gesetzt. Die
Funktion list_insert_sort() hat die meisten Sonderfälle bis jetzt. Der
Quelltext von list_insert() nach dem Kommentar "neues Element am Listen-Kopf
einfügen" wird benutzt um ein neues Element in eine leere Liste einzufügen
oder um ein neues Element am Listen-Kopf einzufügen. Wo liegt der
Unterschied? Bei einer nicht-leeren Liste muss man die Einfüge-Stelle bei
einer sortierten Liste suchen. Die Suche funktioniert mit einem Vergleich.
Wenn ein Datensatz gefunden wird welcher einen höheren value hat als das
neue Element, dann wird vor diesem Datensatz eingefügt. Die Bearbeitung des
Normalfalls benutzt wieder eine for Schleife welche zwei Variablen
manipuliert. Die gleiche for Schleife haben wir für die Funktion
list_delete_value() benutzt, siehe oben.
Das Lesen und Memorieren von gut geschriebenen Quelltext bildet. Wie in
der "normalen" Sprache gibt es in einer Programmiersprache Redewendungen,
Sprichwörter, Floskeln. Irgendein kluger Kopf hat sich die Redewendung vor
Jahren ausgedacht und seit dieser Zeit wird sie durch copy-paste-modify
immer wieder benutzt. Als Informatiker hat man zwei Möglichkeiten: Entweder
man liest viel guten Quelltext oder man muss selbst die Redewendungen
wieder-entdecken. Nun wieder eine Klausur-relevante Frage: Welche
Möglichkeit hört sich nach mehr Arbeit an?
Der letzte Sonderfall betrifft das Einfügen am Ende der Liste. Hier
verwenden wir erstmals die (Zähl)-Variable einer for-Schleife nach der
for-Schleife. An dieser Stelle habe ich in der ersten Version der Funktion
einen schönen Denkfehler gemacht. Anstelle von oldi->next =
pelem habe ich i->next = pelem geschrieben. Ein
unfreundlicher Programmabsturz war die Folge. Bestimmt wissen meine Leser es
besser. Welchen Wert hat i immer wenn die Programmstelle "einfügen am Ende"
erreicht wird?
// list_insert_sort.c
// sortiertes einfuegen
int list_insert_sort(LIST * l, int value_)
{
// neues Element erzeugen
LIST pelem = malloc(sizeof(struct elem));
if (NULL == pelem)
return -1;
pelem->value = value_;
// Sonderfall leere Liste oder
// Sonderfall neues Element am Listen-Kopf einfuegen
if (NULL == *l || (*l)->value > value_) {
pelem->next = *l;
*l = pelem;
return 0;
}
// Normalfall weitere Elemente
LIST i, oldi;
for (oldi = *l, i = oldi->next; i != NULL; oldi = i, i
= i->next) {
if (i->value > value_)
{
pelem->next = i;
oldi->next = pelem;
return
0;
}
}
// Sonderfall einfuegen am Ende
pelem->next = NULL;
oldi->next = pelem;
return 0;
}
int main(int argc, char *argv[])
{
LIST mylist = NULL;
int rv = list_insert_sort(&mylist, 5);
printf("teste einfuegen in leere Liste rv = %d\n",
rv);
list_print(mylist);
rv = list_insert_sort(&mylist, 1);
printf("teste einfuegen am Kopf rv = %d\n", rv);
list_print(mylist);
rv = list_insert_sort(&mylist, 2);
printf("teste einfuegen in der Mitte rv = %d\n", rv);
list_print(mylist);
rv = list_insert_sort(&mylist, 2);
printf("teste einfuegen Duplikat rv = %d\n", rv);
list_print(mylist);
rv = list_insert_sort(&mylist, 9);
printf("teste einfuegen am Ende rv = %d\n", rv);
list_print(mylist);
return 0;
}
Die main() Funktion stellt wieder das Testbett. In der Funktion
list_insert_sort() haben wir vier Fälle behandelt. Im Testbett gibt es aber
fünf Testfälle. Warum? Ich teste auch den Fall das es mehrere
Listen-Elemente mit dem gleichen value gibt. Hier kommt die "Soll"-Ausgabe
des Programms:
teste einfuegen in leere Liste rv = 0
Liste: 5
teste einfuegen am Kopf rv = 0
Liste: 1 5
teste einfuegen in der Mitte rv = 0
Liste: 1 2 5
teste einfuegen Duplikat rv = 0
Liste: 1 2 2 5
teste einfuegen am Ende rv = 0
Liste: 1 2 2 5 9
So langsam geht die Einführung in die einfach verkettete Liste zu Ende.
Wir haben einige Funktionen geschrieben und können diese zu einem
"Application Programming Interface" API zusammenfassen. In der
Programmiersprache C wird hierzu eine Headerdatei benutzt. Unsere
Liste-Implementierung besteht aus der Datenstruktur und fünf
Zugriffsfunktionen. Hier das Listing:
//list.h
typedef struct elem *LIST;
struct elem {
int value;
LIST next;
};
void list_print(LIST l);
int list_insert(LIST * l, int value_);
int list_insert_sort(LIST * l, int value_);
int list_delete(LIST * l);
int list_delete_value(LIST * l, int value_);
Es fällt vielleicht auf das das erste Argument immer vom Typ LIST ist. In
der objektorientierten Programmiersprache C++ wird dieser Objektzeiger
unsichtbar. In der Programmiersprache C können wir objektorientiert denken,
auch wenn wir es nicht direkt hinschreiben können. Es gibt schon einen Grund
warum alle unsere Funktionen mit list_ beginnen.
Die Anweisung if (NULL == *l || (*l)->value > value_) hat noch eine Besonderheit. Das Programm wertet den Ausdruck nur so weit aus bis das Ergebnis feststeht. Der Operator || bedeutet logisches Oder. Wenn der Vergleich NULL == *l korrekt ist (wahr ist), dann wird nicht der zweite Vergleich durchgeführt. Dieses Verhalten ist auch nötig. Bei einer leeren Liste führt die Auswertung von (*l)->value zu einem Programmabsturz. Für die Boole'sche Algebra ist (*l)->value > value_ || NULL == *l identisch zu NULL == *l || (*l)->value > value_. Für die Programmiersprache C aber nicht.
Wer ist der schnellste Läufer? Und wer ist der beste Sortier-Algorithmus?
Informatiker lieben den Wettkampf genauso wie die Leichtathletik-Fans. Nur
bevorzugen Informatiker ihren Wettkampf in geschlossenen Räumen hinter
Computer-Bildschirmen. Um nun Algorithmen vergleichen zu können wurde die
Groß-O Notation erfunden. Wie schneidet unsere Funktion list_insert_sort()
als Sortier-Algorithmus ab? Hier die anschauliche Herleitung: Wie betrachten
den worst-case, den schlechtesten Fall. Für unsere Funktion ist diese
gegeben wenn jedes neue Element als letztes Element in der Liste abgelegt
wird. Das Wandern durch die Liste kostet pro Schritt (pro Durchlauf der
for-Schleife) den Preis von einem Groß-O. Die übliche Schreibweise ist:
Es kostet O(1). Nun betrachten wir das Einfügen von fünf worst-case
Werten in die Liste. Für jeden einzelnen Wert müssen wir die Liste von
Anfang bis Ende durchlaufen. Nun könnten wir eine komplizierte Rechnung
anstellen oder wir können einfach nach dem worst-case fragen. Damit das
fünfte Element seinen Platz am Ende der Liste findet sind O(5)
Arbeitsschritte nötig. Damit wir fünf Elemente in die Liste bekommen müssen
wir fünfmal die Funktion list_insert_sort() aufrufen.
Nun haben wir zwei Angaben. Ein Wert 5 weil für fünf Elemente muss man
fünfmal die Funktion aufrufen und ein O(5) für den worst-case der
Schleifendurchläufe in der Funktion. Der gesamte Aufwand für das Sortieren
ist O(5)*5 oder O(52). Wenn wir nun von 5 Elemente auf N Elemente
gehen, dann lautet das Ergebnis O(N2).
Diese Herleitung der Komplexität der Einfüge-Sortierung (insertion sort)
war anschaulich. Natürlich geht es auch mathematisch streng. Dies kostet
aber viel mehr Platz und sorgt nur für geistige Aussetzer bei den Studenten
des ersten Semesters. Mein persönliches Ziel ist es nicht das 70% bis 80%
der Leser meiner Ausführung nicht folgen können. Oder wie sagte es einmal so
schön ein Professor zu einem anderen Professor: "Hochachtung Herr Kollege.
Ihr neues Buch wird bestimmt ein Standardwerk. Ich habe schon die zweite
Hälfte der Einleitung nicht mehr verstanden".
Der Schwerpunkt dieser Internet-Seite liegt klar bei der
Programmiersprache C. Dies zeigt sich auch in der Literaturliste. Es werden
die "praktischen" Bücher empfohlen. Natürlich ist die Groß-O Notation
interessant, aber es kommt bei unseren Algorithmen ja sowieso immer nur
O(1), O(N), O(log(N)), O(N*log(N)) oder O(N2) heraus, egal wie
lange der Professor an seiner Herleitung bastelt. Die Übersetzung von
rekursiv formulierten Algorithmen in iterative Versionen hat auch nur
begrenzten Nährwert. Hat man das Prinzip einmal verstanden (Rekursion am
Anfang oder Ende ist übersetzbar, Rekursion in der Mitte nicht) wird es
schnell langweilig. Immer interessant bleibt aber das Handwerk: Eine
Programmiersprache so gut zu lernen das man sich in dieser Sprache
ausdrücken kann. Mein Ziel war es Ihnen viele gute Sprach-Beispiele zu
liefern.
Kurzer Lebenslauf: Ausbildung bei Siemens AG, Studium der Informatik,
seit 24 Jahren verschiedene Tätigkeiten entlang des "software life cycle"
bei der Deutschen Flugsicherung GmbH. Ich bin Kinder-lieb, Tier-lieb und
Studenten-lieb. Ich habe eine gewisse Neigung zum dozieren (Lehrer-Syndrom)
und schreibe deshalb mangels eigener Studenten diese Web-Seite.
